I believe the store is going to be launched with the release of HISE 5
Posts
-
RE: Cannot access HISE Storeposted in Bug Reports
-
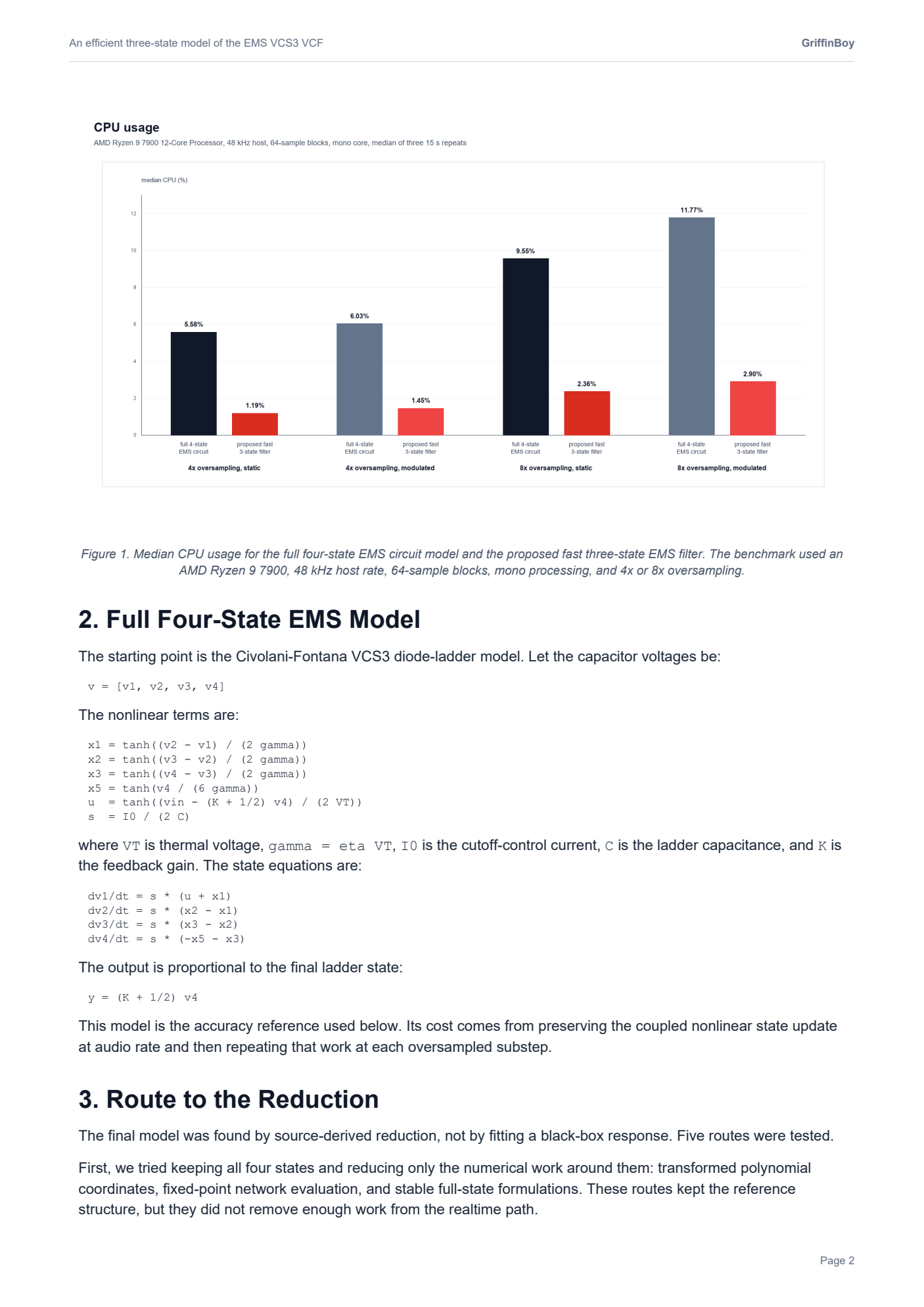
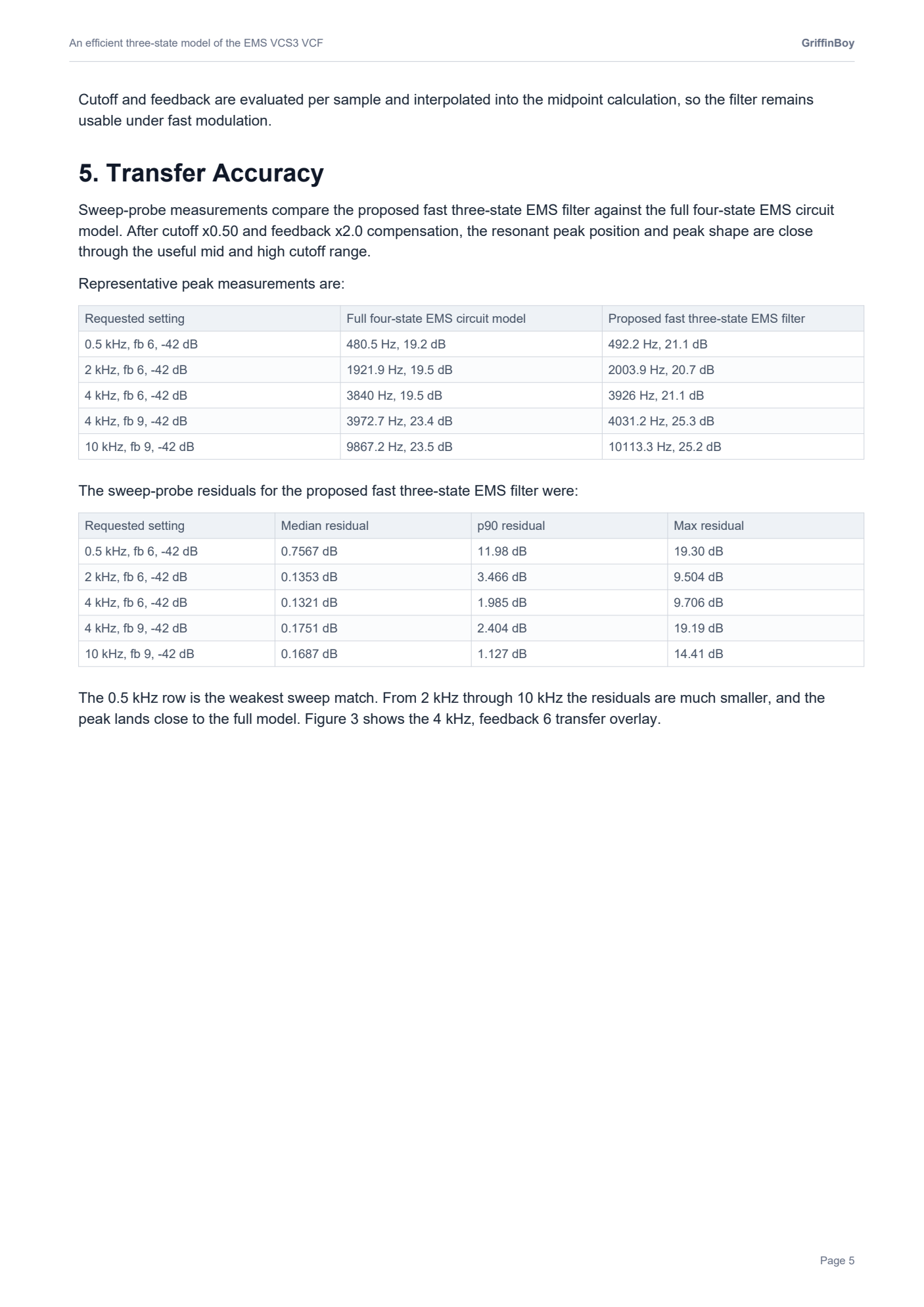
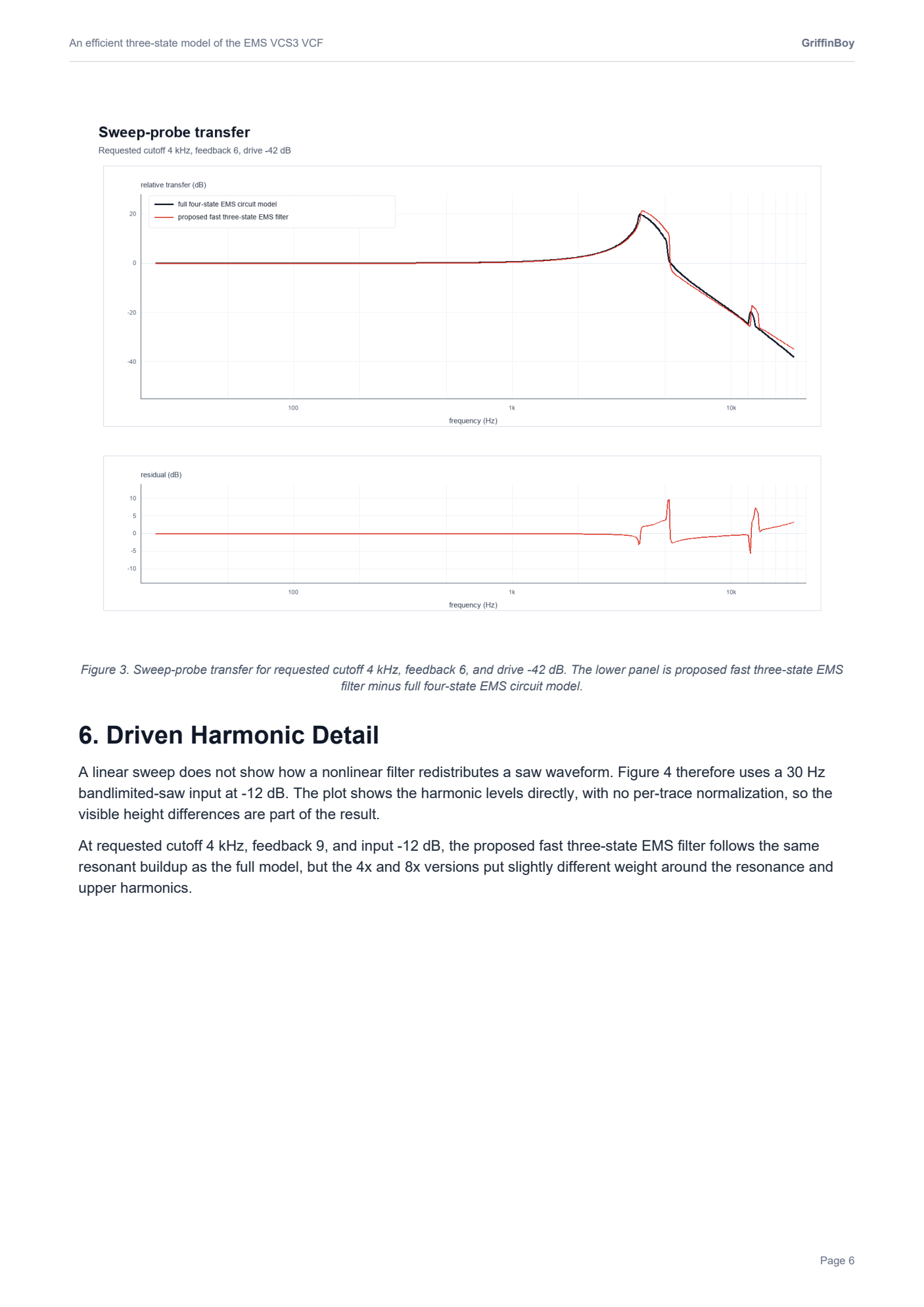
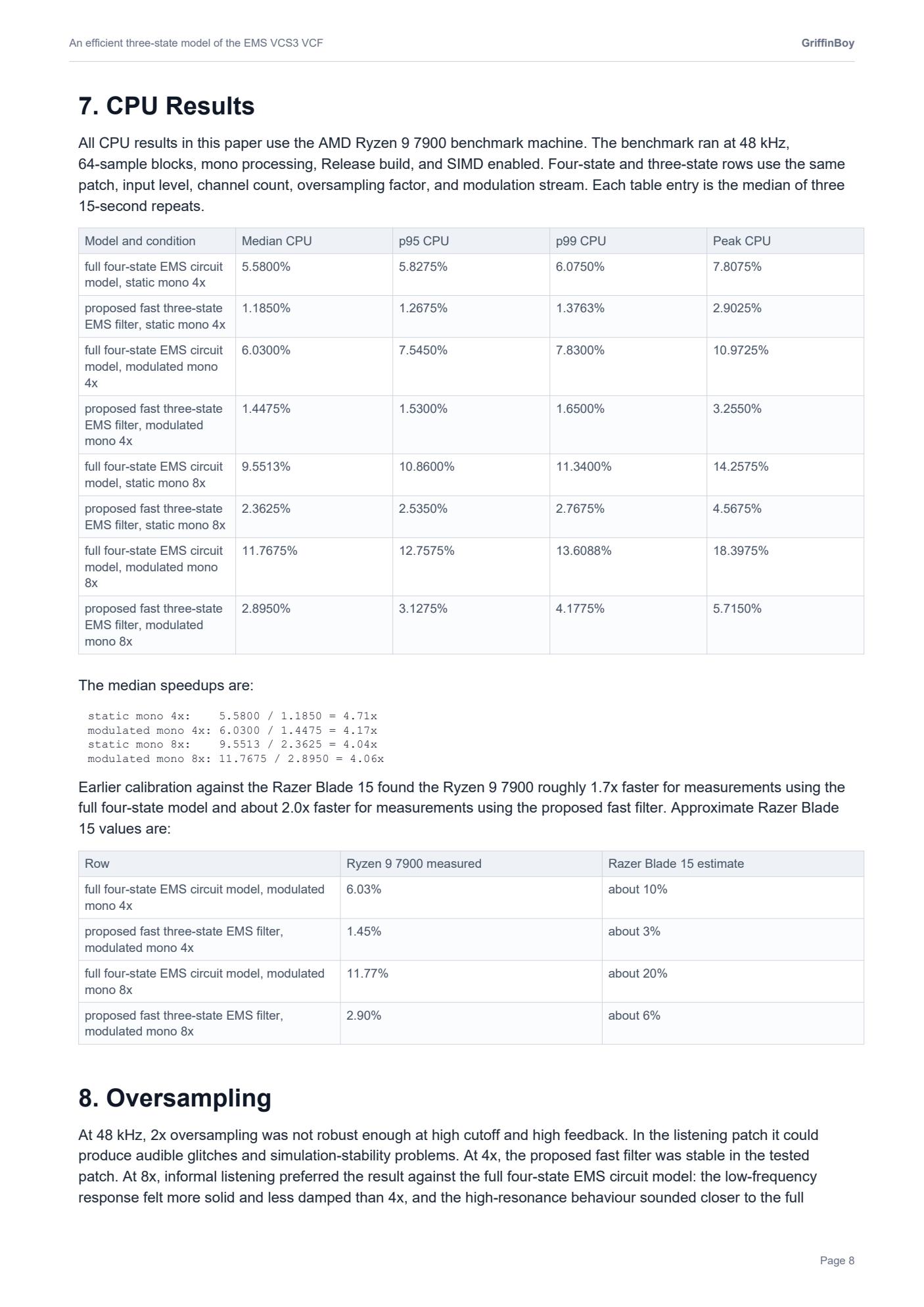
RE: [Research Paper] An Efficient Simulation of the EMS VCS3 Filter *updated with audio comparison examplesposted in C++ Development
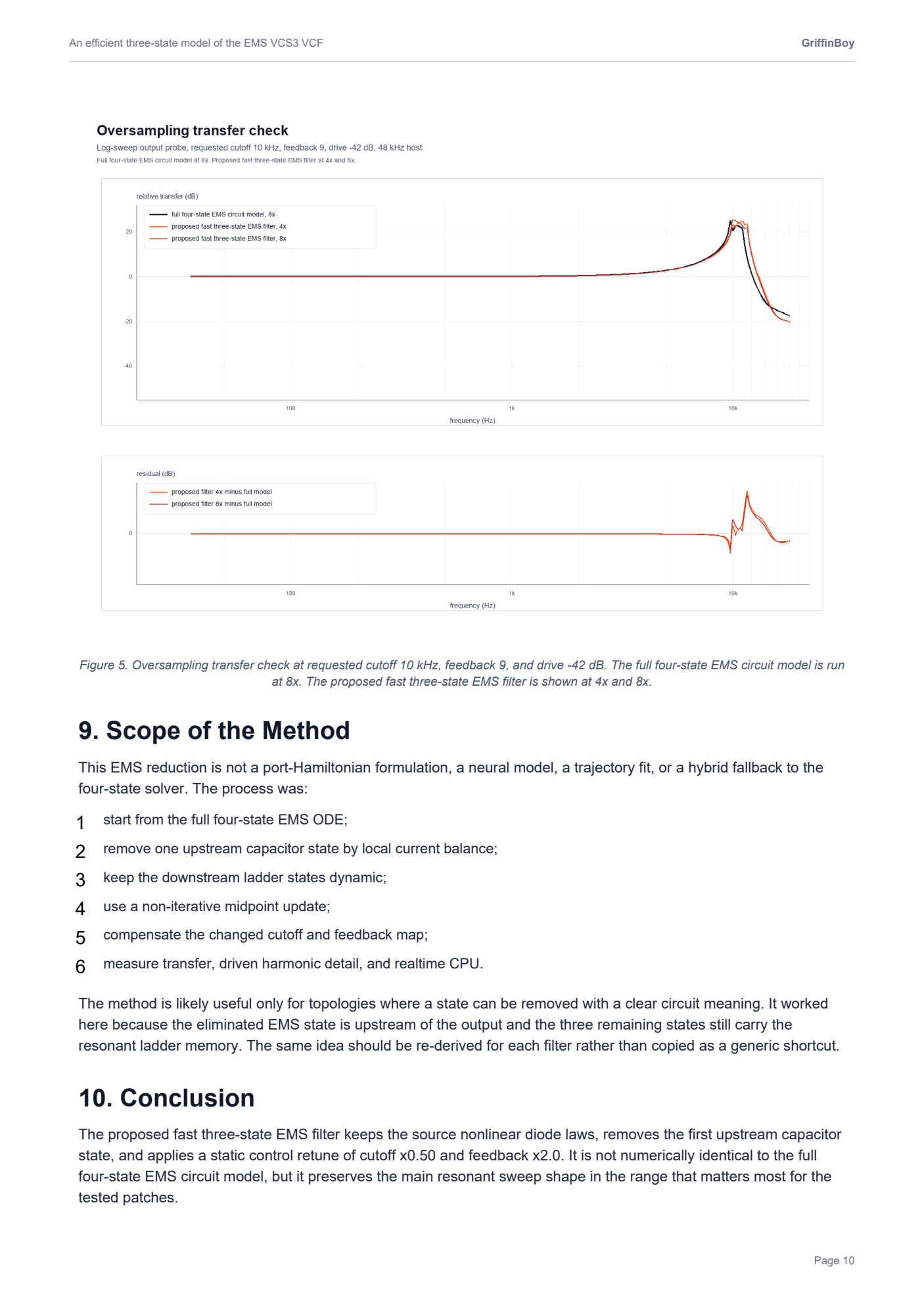
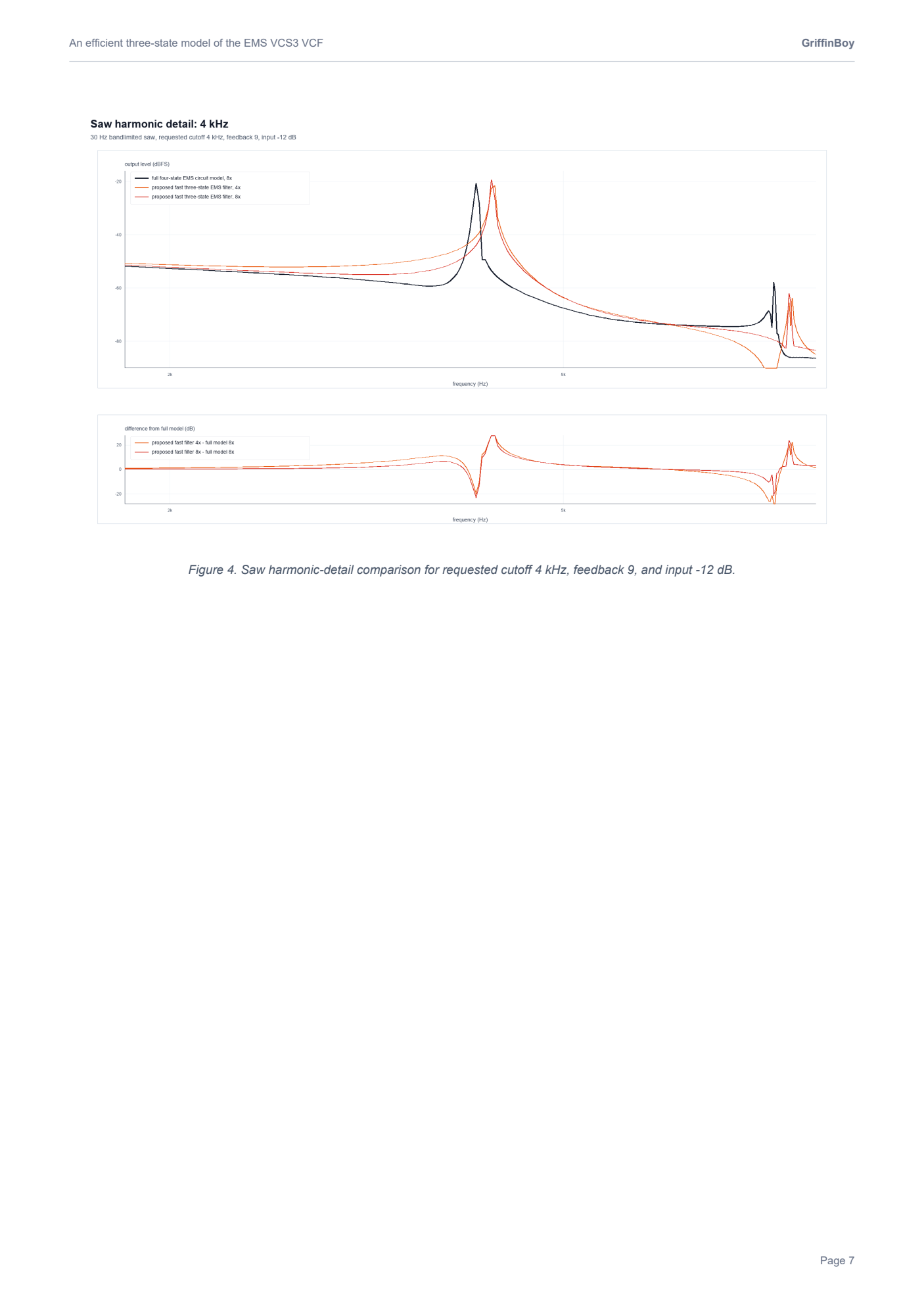
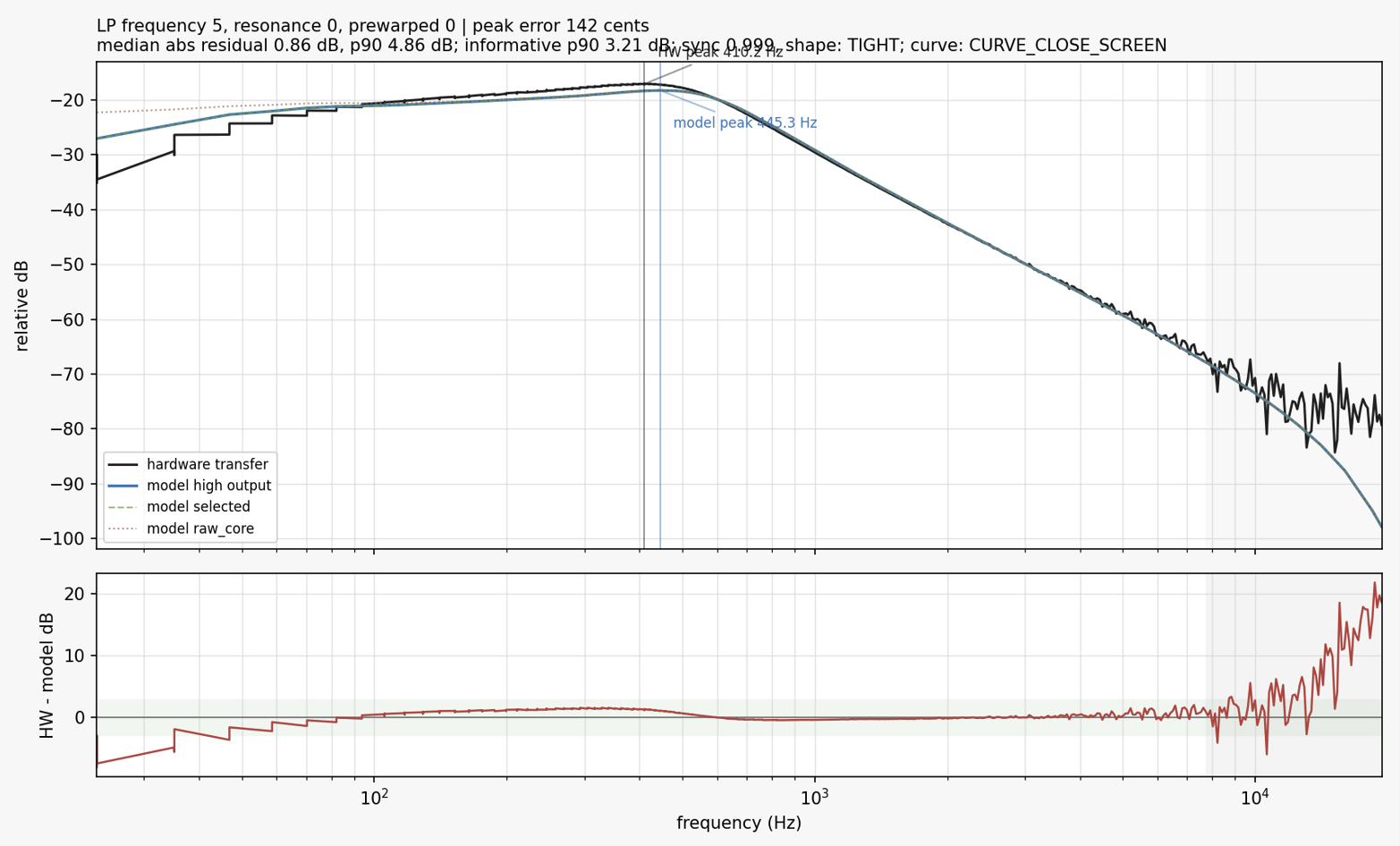
I realized that these plots are a little misleading.
The VCS3 filter is highly nonlinear and "bubbles" and so taking a measurement of frequency response is quite difficult since the filter is moving around on it's own accord all the time...!
Here is a more detailed FFT that shows how the filters do match more closely than the graphics in my paper would suggest.
.
Black is the slow accurate VCS3, Red is my optimized VCS3.
Not oversampled.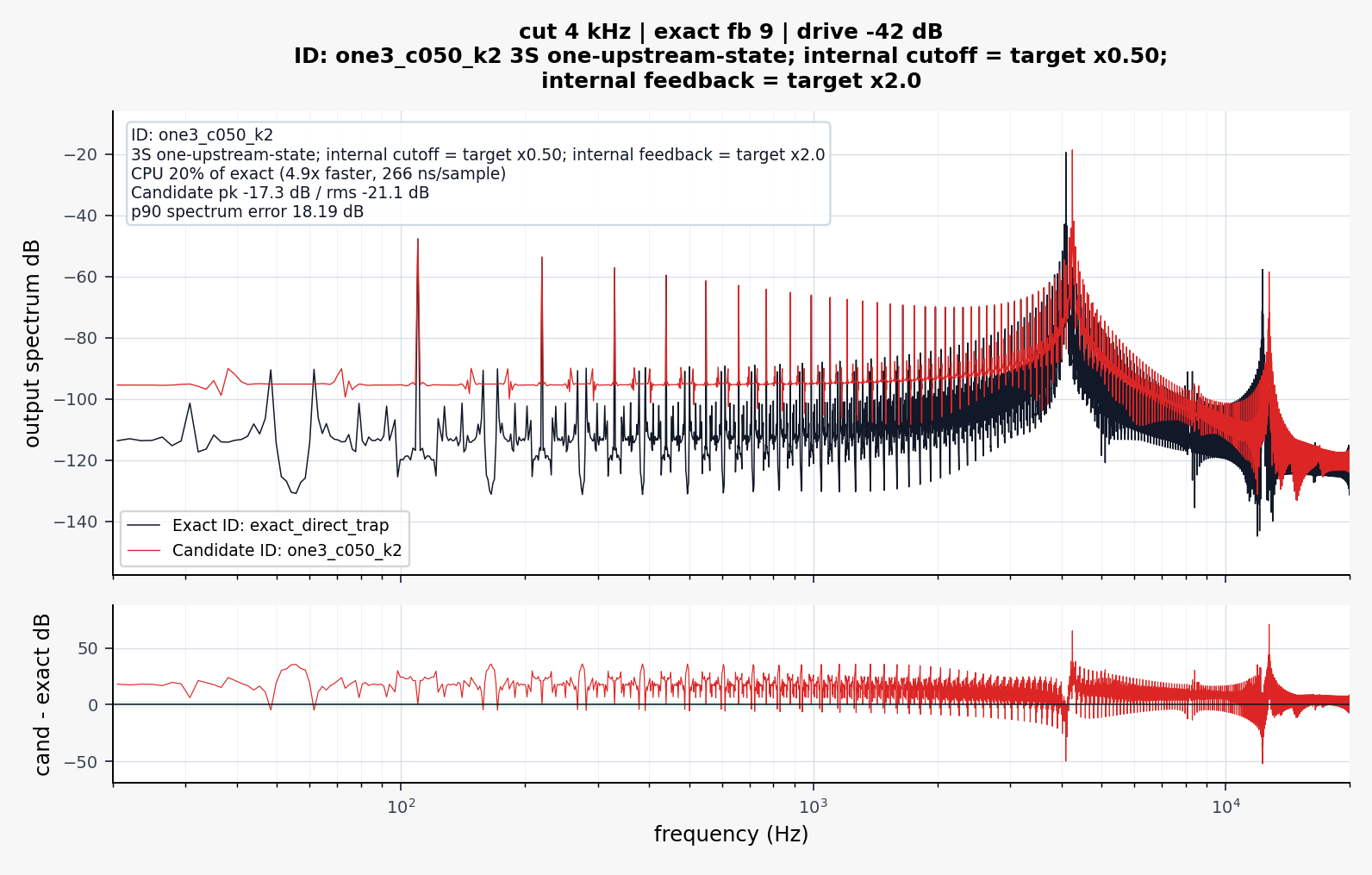
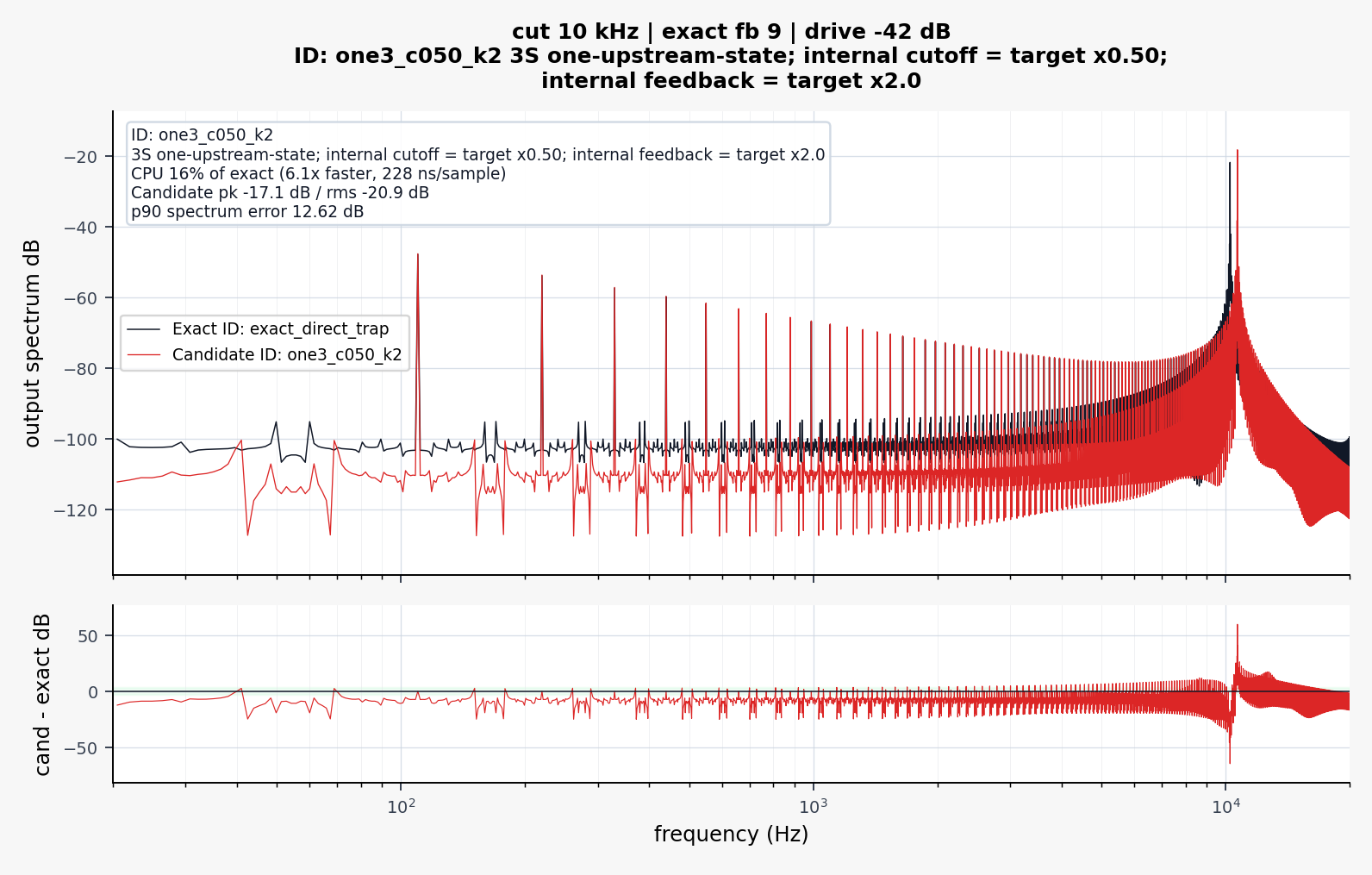
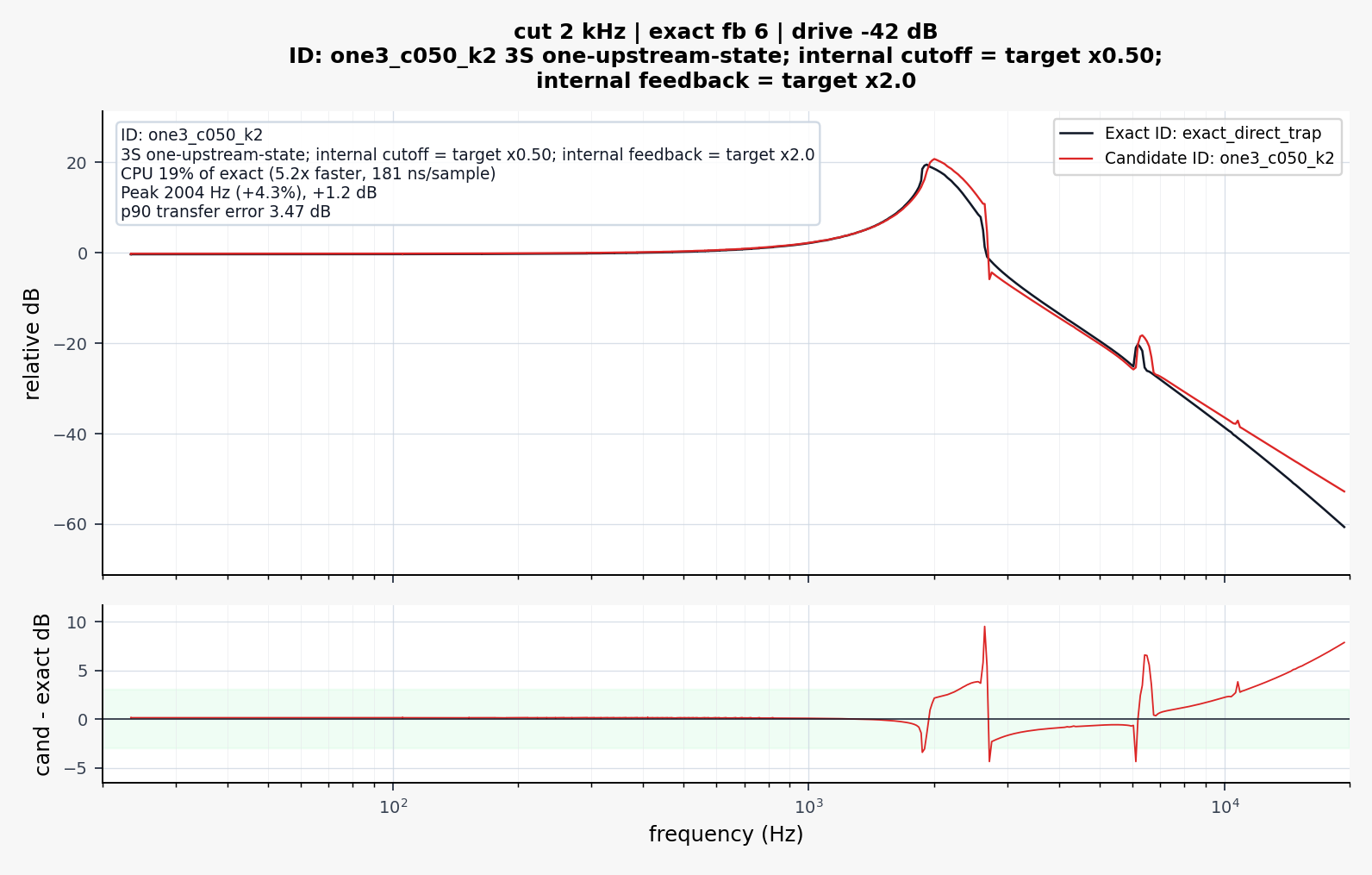
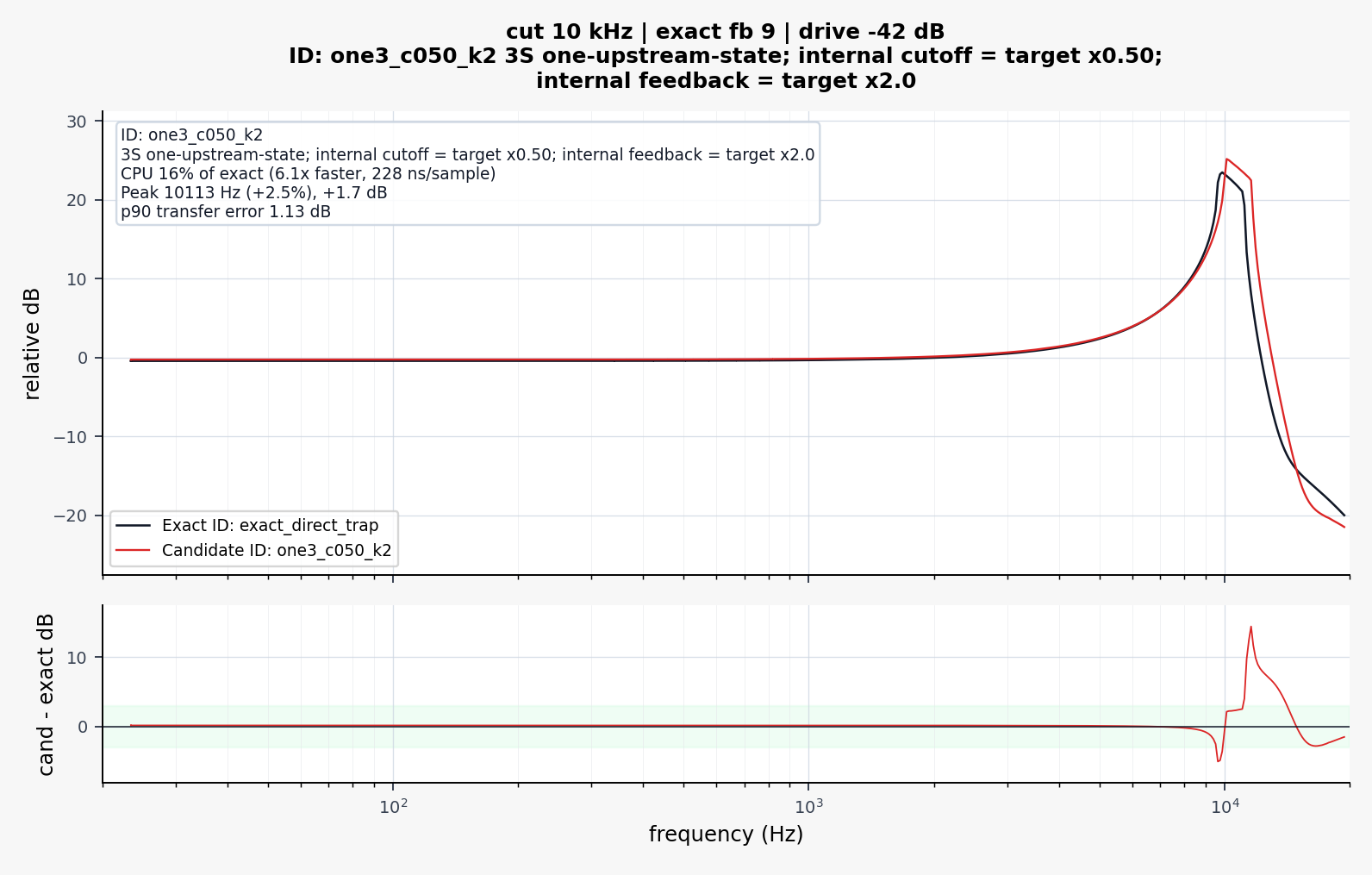
When oversampled, I found the proposed model to be perceptually close to the slower accurate model. The resonance and cutoff and gain values differ slightly, but the important aspects of the filter are retained.
-
[Research Paper] An Efficient Simulation of the EMS VCS3 Filter *updated with audio comparison examplesposted in C++ Development
I've been wanting to share some of my R&D for a while -
I'm constantly creating new DSP on commission, but I'm always short on time to talk about it because I am buried under work (the aforementioned R&D).At some point I had the realisation that maybe one of these newer AI agentic models could look at my code and scribbles, and mock up something vaguely paper-shaped from it.
I then edited it by hand to add more details, and check correctness.
The result surprisingly wasn't too bad and I've checked that all the math and facts are correct.
So I'm sharing it here for those who are scientifically inclined, or just interested in the implementation side of this kind of DSP work.At a later date I'll rewrite the paper by hand and post a cleaner version.
Audio comparison companion.



(continues in comments)
-
[Bug] Enabling NUM_HARDCODED_FX_MODS breaks custom C++ nodes.posted in Bug Reports
Hardcoded Master FX parameter modslots can force c++ Third-party node parameters to max
*I used ChatGPT to help format this bug report so that it's written clearly and thoroughly.
I apologize for the "Ai aesthetic" residue that leaves behind.Branch: I'm on the latest HISE develop branch, pulled and compiled today
OS: Windows 11
Juce: I'm using Juce 6 (version: 6.1.3)
Project flags:NUM_HARDCODED_FX_MODS=8 NUM_HARDCODED_POLY_FX_MODS=8Summary
I think there is a bug in the hardcoded Master FX "parameter-modslot" path.
I didn't want to post a report until I was sure it wasn't my own mistake, but I've been reading the Hise source all day and testing different C+ nodes and in the end I concluded this might be a bug:If a third-party node exposes a parameter modslot with
ConnectionMode::Parameter, loading that node into a hardcoded Master FX forces the modslot parameter values to get set to the top of their ranges (and stuck there).This is not a small issue. For DSP nodes it completely breaks effects, and means you can't use any c++ nodes that have modslots inside monophonic hardcoded master FX.
I like almost all of my c++ nodes to have modslots so that they can work easily with hise modulation and the matrix modulator. This bug means I have to make modslot and non-modslot versions of every effect, so that I can load the modslot version into poly contexts and the non-modslot one into mono contexts. And then for the mono nodes I have to use a different modulation scheme. Messy.
(unless I'm misunderstanding something).How I found it
I was testing a compiled third-party DSP node.
The same node behaved normally in a ScriptFX context, but in a hardcoded Master FX it produced broken / glitchy / extremely wrong output.
When I removed these project flags and rebuilt, the hardcoded Master FX version started behaving normally again:
NUM_HARDCODED_FX_MODS=8 NUM_HARDCODED_POLY_FX_MODS=8So the issue appears to be tied to hardcoded FX modslots.
Disabling those flags is not a usable workaround for me, because then hardcoded modslots would be unavailable project-wide.
Minimal test
I made four tiny diagnostic third-party nodes.
Each node has one parameter:
Parameter_name: ProbeValue Range: 0.0 to 1.0 Default: 0.25Each node outputs a tone whose gain follows
ProbeValue.Expected result: quiet tone.
Bug result if the parameter is forced to max: much louder tone.Each node exposes the same parameter slot:
modulation::ConnectionInfo slot; slot.connectedParameterIndex = ProbeValueParameter; slot.connectionMode = modulation::ConnectionMode::Parameter; slot.modulationMode = modulation::ParameterMode::ScaleAdd;I tested four variants:
Griffin_ModSlotProbe_NoHandle Griffin_ModSlotProbe_WithHandle Griffin_ModSlotProbe_FrameHandle Griffin_ModSlotProbe_ModNodeHandleThese check whether adding the following details would fix or change the behavior:
- no
handleModulation()function defined handleModulation(double&) { return 0; }- block processing forwarded through
processFrame()from process() isModNode() == true(yeah, I know that's not going to do anything)
Result
In hardcoded Master FX:
NoHandle left loud, right silent WithHandle left loud, right silent FrameHandle left loud, right silent ModNodeHandle left loud, right silentThe left channel becoming loud proves
ProbeValuewas driven from0.25to1.0.
And the right channel staying silent meanshandleModulation(double&)callback was not called.Expected behaviour
Ideally, a hardcoded Master FX parameter modslot should not push a node parameter to its maximum value simply because the slot exists.
If no meaningful modulation value is active, the parameter should keep its current/default value, or the slot should not be treated as connected until there is an actual usable modulation connection.
Current behaviour
Currently, with hardcoded FX modslots enabled, a third-party C++ node exposing
ConnectionMode::Parametercan get seemingly spammed with max-range parameter values during rendering / stuck at max value (moving the parameter doesn't unstick us, the parameters are stuck to max).Why this matters
I'm assuming that HISE nodes are intended to be modular.
If that's true, then a node that is poly-capable, or a node that exposes modslots, should be able to function in a mono hardcoded Master FX context too.This is also inconvenient for my shipped products. A HISE user can load one of my nodes into HISE and get broken DSP because the hardcoded Master FX modulation path corrupts parameter values.
The result of all this is that
ConnectionMode::Parameterbecomes unsafe for third-party hardcoded Master FX products.Suspected source bug
The Hise algorithm seems to do something like this:
HardcodedMasterFX::applyEffect() -> extraMods.processChunkedWithModulation(rd) -> ExtraModulatorRuntimeTargetSource::handleModulation(...) -> ModChainWithBuffer::getOneModulationValue(startSample) -> rd.handleModulation(pIndex, mv) -> parameter range convertFrom0to1(mv) -> p->callback.call(value)The important part is in the hardcoded Master FX context, with no active voice state,
getOneModulationValue()can return an inactive/default modulation value of1.0f.That normalized
1.0is then converted through the parameter range, so the node receives the parameter maximum.Request
Could the hardcoded Master FX parameter-modslot path be changed so inactive / unconnected / not-yet-valid modulation does not force parameter-mode slots to max?
post script: a similar / related bug exists in the Hise synth group, I will write a report on that after a bit more investigation.
Christoph, Thanks for all your hard work🫡
- no
-
RE: VST/plugin GUI design + launch graphics — ads, motion, webposted in General Questions
Ah that makes sense,
yes indeed that was the only thing.In that case, great work all round.
I'll keep you in mind for some upcoming projects. -
RE: VST/plugin GUI design + launch graphics — ads, motion, webposted in General Questions
The AI textures aren't my favorite.
But the majority of the image looks great.
I like the knobs a lot, and the VU meter is quite elegant! -
RE: [Devlog] Blogposted in C++ Development
@resonant
Ah! So, you might have heard tell of an upcoming Hise Asset store?
I don't know the exact plans, but it might be released with the next major Hise version.I'm hoping to release a giant bulk of DSP on that platform when it launches, all vetted by Christoph beforehand.
I've been holding off on releasing any DSP nodes on the forum, in the hope that the store could become an official home for all of them.I've made a lot of products in advance:
(195 Dsp files in my "approved" folder)Including some free stuff that I've made for the HISE community.
I don't currently have an existing storepage for my work, but I do take commissions and licence out my DSP on a per-person basis, so if there is anything in particular you are looking for, feel free to send me a direct message!
-
[Devlog] Blogposted in C++ Development
It has been a while since I've posted any tutorial content.
I had a brief moment where I released (a single?) guide for making c++ nodes in HISE.
Some of you probably gave up hope that I'd make another tutorial on the topic.
But I had always intended to do a full deep dive into C++ DSP, and I've been biding my time waiting for the opportune moment where I would have enough free time to make the content.Well, the time is upon us, and I'm finally making the content - in the form of HISE blogs.
I'm still in the process of designing the blog posts,
but once I've built enough graphics and animations, I should be able to pump out regular posts that explore different areas of audio coding and science.The posts will likely start out quite simple,
but I plan to dive into some of the advanced modern topics as well, not limited to: neural effects, analog circuit simulation that nulls against hardware, and other topics that I've been writing research papers about.Looking forward to discussing with you all soon!
[work in progress, HISE blogpost development]
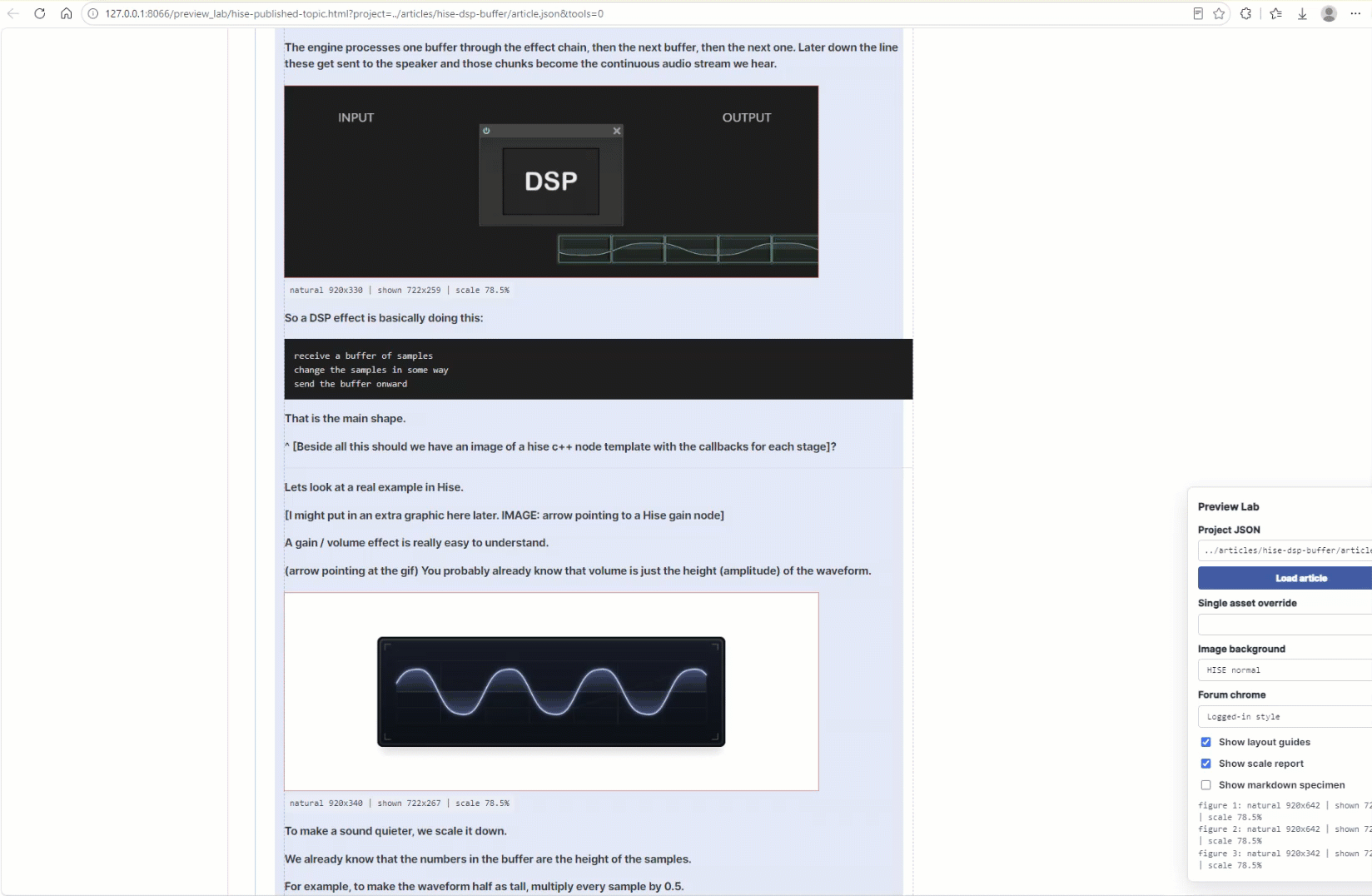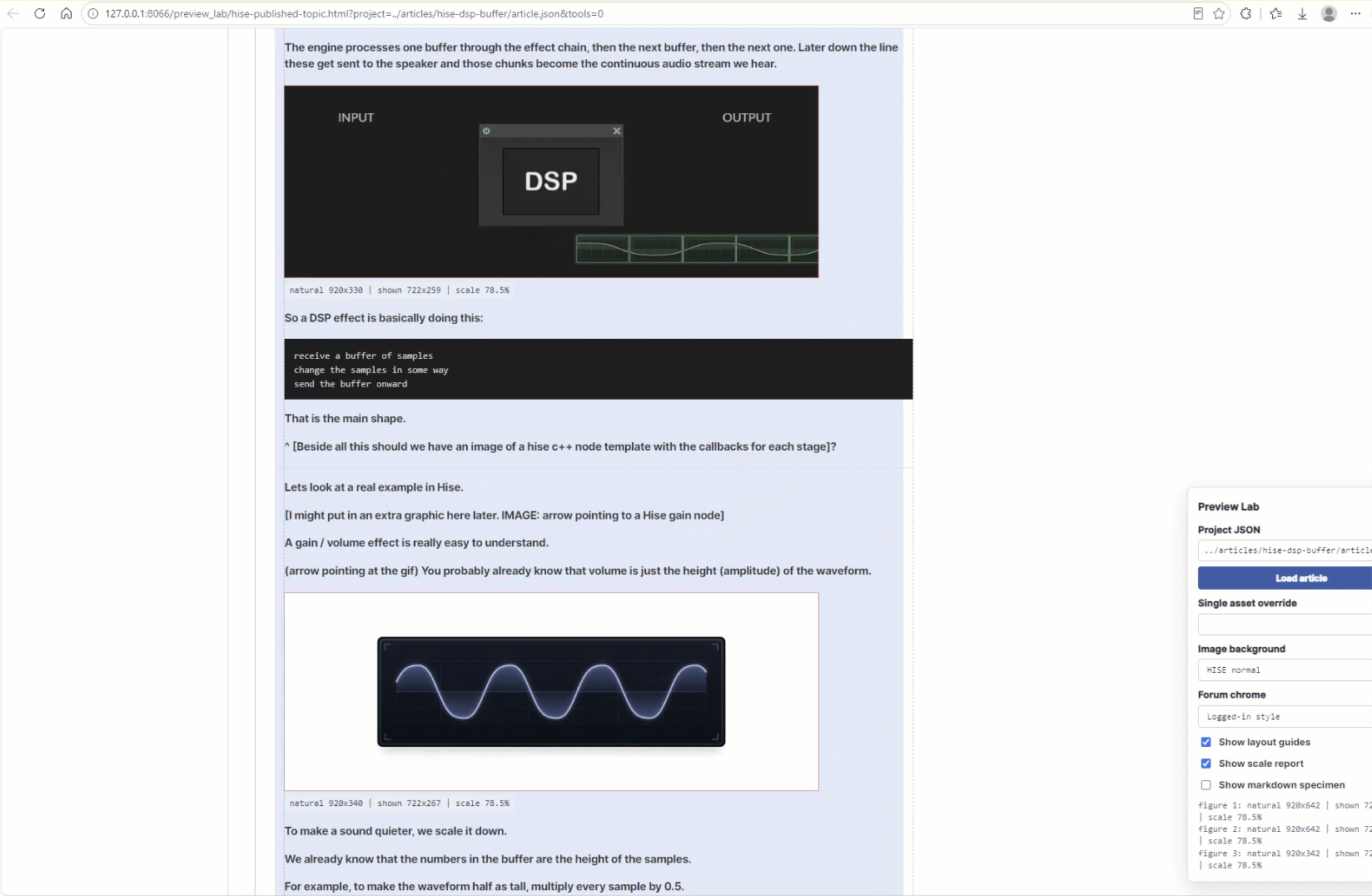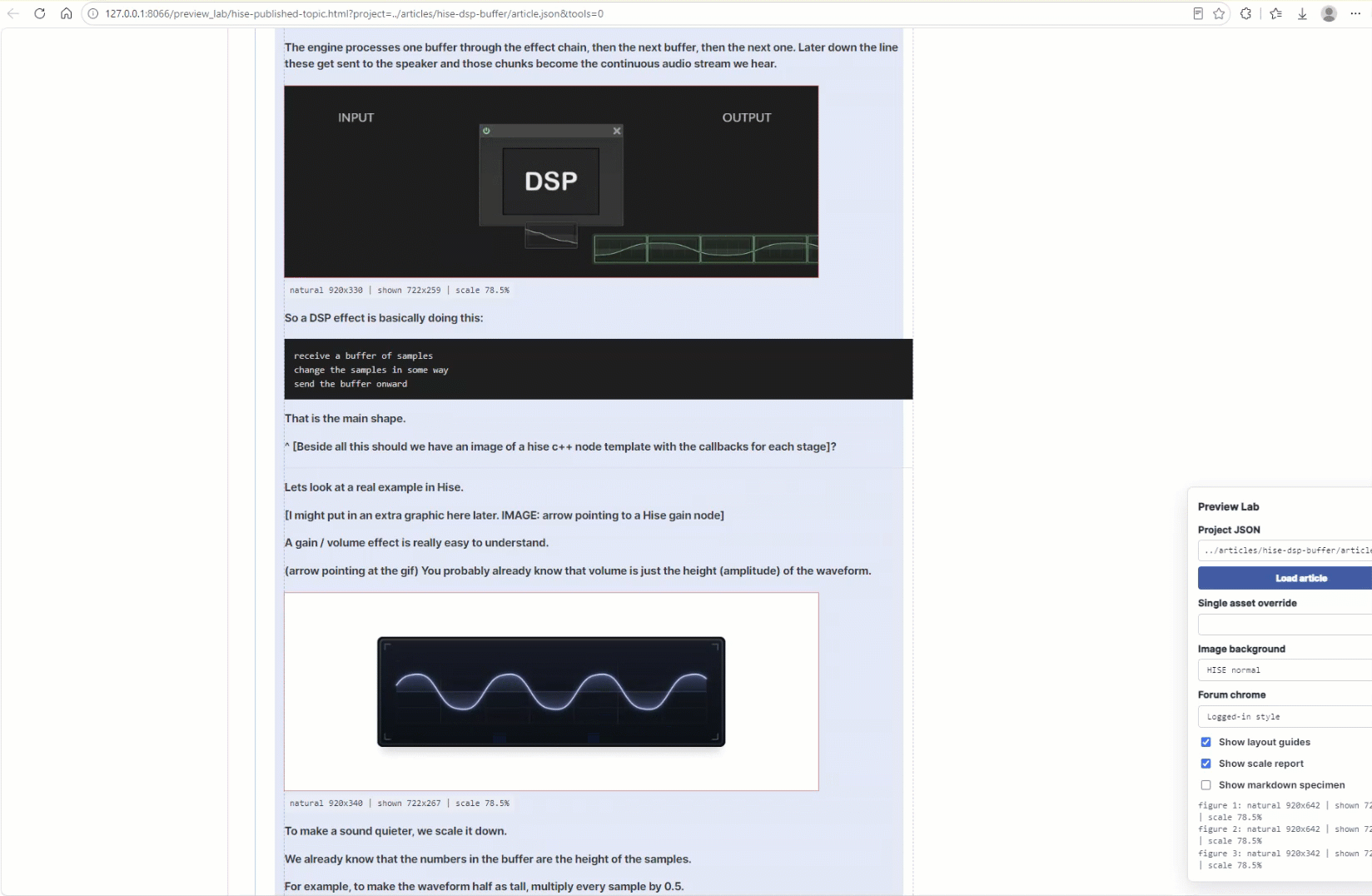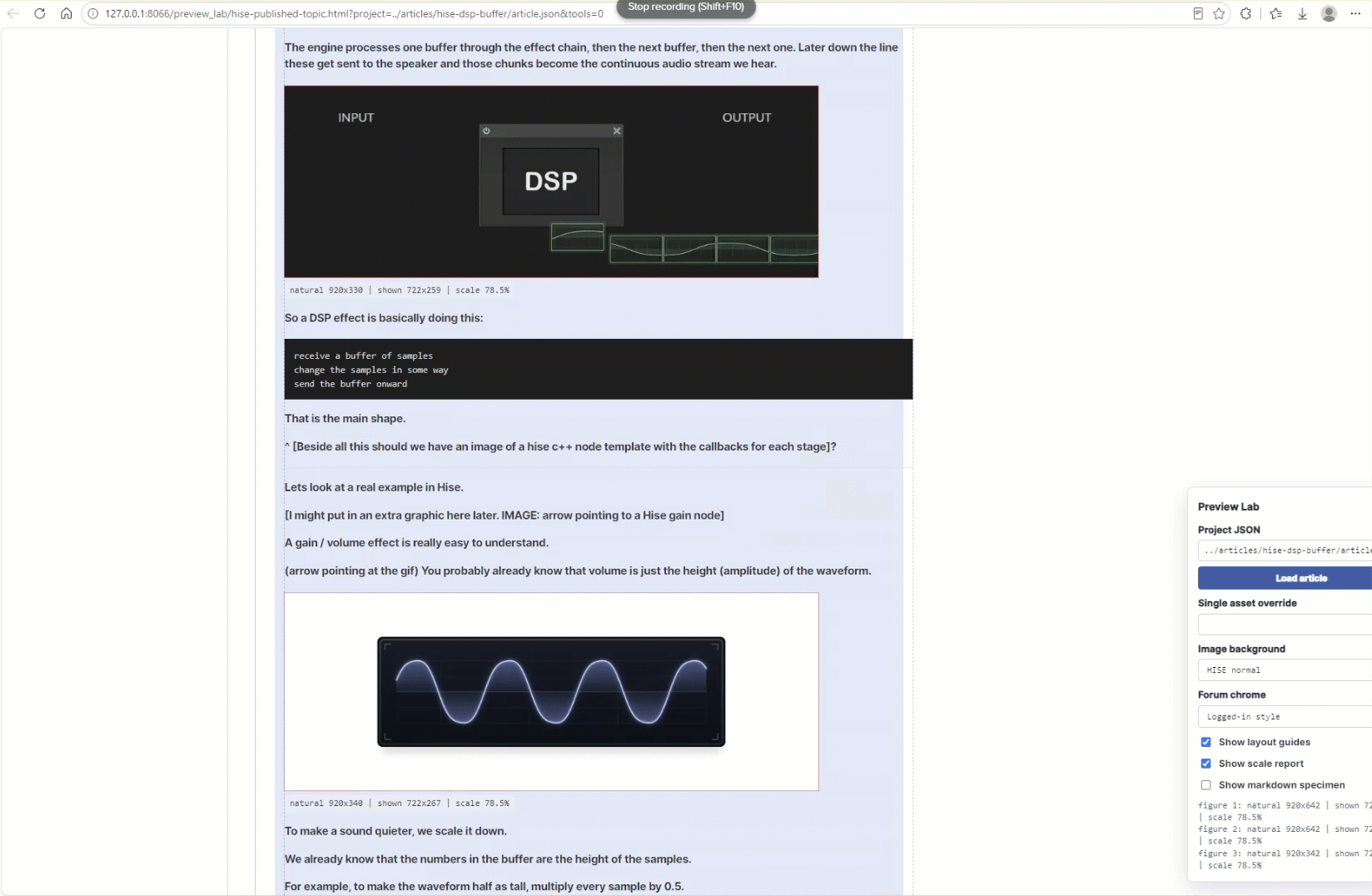
[project: analog filter model, new simulation method]
Yes... this is a blog post about devloping a blog post.
-
RE: C++ Global Cables // How to add multiple cables to an existing compiled network.posted in Scripting
I don't have a "clean" example.
This is old code too, so not a good example of good c++ node practices or anything like that.But here is a c++ node with a global cable(s) set up.
I've had no problems before, with updating existing c++ headers when adding more global cables.
If you make sure that the generated global cable code is up to date.
When you create more cables, you need to re-generate the global cable c++ code in Hise and update those parts in the c++This generated stuff needs to be kept up to date with the cable names and IDs in your Hise project:
enum class GlobalCables { grainpos = 0 }; using cable_manager_t = routing::global_cable_cpp_manager<SN_GLOBAL_CABLE(94428153)>;^ Here, only one global cable exists, however when you add more global cables to your Hise project, this code will need regenerating / updating with the new names and IDs of the cables in your Hise project.
C++ node example (using one global cable):
// FILE: Griffin_GrainOsc.h /* Granular OSC node: per-voice state & note-reactive pitch. Each voice owns a Granulator instance via snex::PolyData so reset/prepare are scoped to the active voice. Pitch maps so that MIDI note 60 plays the sample at its original pitch / speed */ #pragma once #include <JuceHeader.h> #include <array> #include <vector> #include <deque> #include <cmath> #include <atomic> #include "src/GriffinGrainOsc/GGO_GranularEngine.h" namespace project { using namespace juce; using namespace hise; using namespace scriptnode; enum ParamID { kGrainSizeMs, kDensityHz, kMainPos, kSpray, kPitchSt, kRandPitch, kRandSize, kStereoSpread, kReverseChance, kEnvMode, kMaxGrains, kNumParams }; enum class GlobalCables { grainpos = 0 }; using cable_manager_t = routing::global_cable_cpp_manager<SN_GLOBAL_CABLE(94428153)>; template<int NV> struct Griffin_GrainOsc : public data::base, public cable_manager_t { SNEX_NODE(Griffin_GrainOsc); struct MetadataClass { SN_NODE_ID("Griffin_GrainOsc"); }; static constexpr bool isModNode() { return false; } static constexpr bool isPolyphonic() { return NV > 1; } static constexpr bool hasTail() { return false; } static constexpr bool isSuspendedOnSilence() { return false; } static constexpr int getFixChannelAmount() { return 2; } static constexpr int NumTables = 0, NumSliderPacks = 0, NumAudioFiles = 1, NumFilters = 0, NumDisplayBuffers = 0; struct Voice { ggrain::Granulator<float> gran; uint32_t lastGrainSm{ 0 }; double lastDensityHz{ -1.0 }; int note{ 60 }; double sr{ 44100.0 }; void prepare(double sampleRate) { sr = sampleRate; gran.prepare(sr); lastGrainSm = 0; lastDensityHz = -1.0; } void reset() { gran.prepare(sr); // keeps grains cleared, parameters intact lastGrainSm = 0; lastDensityHz = -1.0; } void setSample(const float* mono, uint32_t num, double fileSr) { gran.loadSample(mono, num, fileSr); } }; template<typename PD> void process(PD& d) { auto& fix = d.template as<snex::Types::ProcessData<2>>(); auto blk = fix.toAudioBlock(); float* L = blk.getChannelPointer(0); float* R = blk.getChannelPointer(1); auto& v = voices.get(); v.gran.process(L, R, d.getNumSamples()); flushSpawnEvents(); } void prepare(snex::Types::PrepareSpecs s) { sr = s.sampleRate; voices.prepare(s); for (auto& v : voices) { v.prepare(sr); v.gran.setSpawnCallback(&Griffin_GrainOsc::onSpawnThunk, this); v.gran.setSpawnInfoCallback(&Griffin_GrainOsc::onSpawnInfoThunk, this); } // Leave existing param cache alone in runtime use; these are only defaults for first-time init. params[kGrainSizeMs] = (params[kGrainSizeMs] == 0.0 ? 100.0 : params[kGrainSizeMs]); params[kDensityHz] = (params[kDensityHz] == 0.0 ? 5.0 : params[kDensityHz]); params[kMainPos] = (params[kMainPos] == 0.0 ? 0.5 : params[kMainPos]); params[kSpray] = (params[kSpray] == 0.0 ? 0.0 : params[kSpray]); params[kPitchSt] = params[kPitchSt]; // keep params[kRandPitch] = params[kRandPitch]; params[kRandSize] = params[kRandSize]; params[kStereoSpread] = params[kStereoSpread]; params[kReverseChance] = params[kReverseChance]; params[kEnvMode] = (params[kEnvMode] == 0.0 ? 2.0 : params[kEnvMode]); for (auto& v : voices) params[kMaxGrains] = (double)v.gran.capacity(); applyParamsAll(); qCount.store(0, std::memory_order_relaxed); seq.store(0, std::memory_order_relaxed); } template<int P> void setParameter(double v) { static_assert(P < kNumParams); params[P] = v; for (auto& voice : voices) applyParamsForVoice(voice); } void createParameters(ParameterDataList& data) { using PD = parameter::data; PD pSize("GrainSizeMs", { 1.0, 2000.0, 0.01 }); pSize.setDefaultValue(100.0); pSize.setSkewForCentre(100.0); registerCallback<kGrainSizeMs>(pSize); data.add(pSize); PD pDen("DensityHz", { 0.1, 200.0, 0.0001 }); pDen.setDefaultValue(5.0); pDen.setSkewForCentre(10.0); registerCallback<kDensityHz>(pDen); data.add(pDen); PD pPos("Position", { 0.0, 1.0, 0.0001 }); pPos.setDefaultValue(0.0); registerCallback<kMainPos>(pPos); data.add(pPos); PD pSpr("Spray", { 0.0, 1.0, 0.0 }); pSpr.setDefaultValue(0.0); pSpr.setSkewForCentre(0.2); registerCallback<kSpray>(pSpr); data.add(pSpr); PD pPst("PitchSt", { -36.0, 36.0, 0.001 }); pPst.setDefaultValue(0.0); registerCallback<kPitchSt>(pPst); data.add(pPst); PD pRP("RandPitch", { 0.0, 1.0, 0.0 }); pRP.setDefaultValue(0.0); pRP.setSkewForCentre(0.08); registerCallback<kRandPitch>(pRP); data.add(pRP); PD pRS("RandSize", { 0.0, 1.0, 0.0001 }); pRS.setDefaultValue(0.0); pRS.setSkewForCentre(0.4); registerCallback<kRandSize>(pRS); data.add(pRS); PD pSpread("RandPan", { 0.0, 1.0, 0.0001 }); pSpread.setDefaultValue(0.0); pSpread.setSkewForCentre(0.35); registerCallback<kStereoSpread>(pSpread); data.add(pSpread); PD pRev("ReverseChance", { 0.0, 1.0, 0.0001 }); pRev.setDefaultValue(0.0); pRev.setSkewForCentre(0.4); registerCallback<kReverseChance>(pRev); data.add(pRev); PD pEnv("EnvelopeShape", { 0.0, 2.0, 1.0 }); pEnv.setDefaultValue(2.0); registerCallback<kEnvMode>(pEnv); data.add(pEnv); PD pCap("MaxVoiceGrains", { 1.0, (double)128.0, 1.0 }); pCap.setDefaultValue((double)128.0); registerCallback<kMaxGrains>(pCap); data.add(pCap); } /* Safe sample load: - Push newest buffer. - Point all voices at newest buffer (Granulator snapshots pointer/size). - Compact pool keeping newest and any buffers still used by active grains. */ void setExternalData(const snex::ExternalData& ed, int) override { using DT = snex::ExternalData::DataType; if (ed.dataType != DT::AudioFile) return; if (ed.isXYZ()) return; if (ed.isEmpty()) return; if (ed.numChannels <= 0 || ed.numChannels > 2) return; if (ed.numSamples <= 0 || ed.sampleRate <= 0.0) return; auto buf = ed.toAudioSampleBuffer(); const int nc = buf.getNumChannels(); const int ns = buf.getNumSamples(); if (ns <= 0 || (nc != 1 && nc != 2)) return; const double maxSec = 600.0; const int cap = juce::jmin(ns, (int)juce::roundToInt(ed.sampleRate * maxSec)); SampleBuf newest; newest.data.resize((size_t)cap); if (nc == 1) { const float* s0 = buf.getReadPointer(0); for (int i = 0; i < cap; ++i) { float x = s0[i]; if (!std::isfinite(x)) x = 0.0f; newest.data[(size_t)i] = juce::jlimit(-1.0f, 1.0f, x); } } else { const float* L = buf.getReadPointer(0); const float* R = buf.getReadPointer(1); for (int i = 0; i < cap; ++i) { float x = 0.5f * (L[i] + R[i]); if (!std::isfinite(x)) x = 0.0f; newest.data[(size_t)i] = juce::jlimit(-1.0f, 1.0f, x); } } newest.srcRate = ed.sampleRate; pool.push_back(std::move(newest)); const size_t newestIdx = pool.size() - 1; const float* newestPtr = pool[newestIdx].data.data(); const uint32_t newestSz = (uint32_t)pool[newestIdx].data.size(); const double newestSR = pool[newestIdx].srcRate; for (auto& v : voices) v.setSample(newestPtr, newestSz, newestSR); if (pool.size() <= 1) return; size_t write = 0; for (size_t read = 0; read < pool.size(); ++read) { const bool keepNewest = (read == newestIdx); bool keep = keepNewest; if (!keepNewest) { const float* p = pool[read].data.data(); for (auto& v : voices) { if (v.gran.isSamplePointerInUse(p)) { keep = true; break; } } } if (keep) { if (write != read) pool[write] = std::move(pool[read]); ++write; } } pool.resize(write); } void reset() { for (auto& v : voices) { v.reset(); // clear grains; keep parameters/seeds/buffers applyParamsForVoice(v); } qCount.store(0, std::memory_order_relaxed); } void handleHiseEvent(HiseEvent& e) { if (e.isNoteOn()) { auto& v = voices.get(); v.gran.flush(true); v.note = e.getNoteNumberIncludingTransposeAmount(); applyParamsForVoice(v); } } SN_EMPTY_PROCESS_FRAME; void connectToRuntimeTarget(bool addConnection, const runtime_target::connection& c) override { cable_manager_t::connectToRuntimeTarget(addConnection, c); } private: // GUI spawn-event sender juce::Array<juce::var> packed; void flushSpawnEvents() { const int N = qCount.exchange(0, std::memory_order_acq_rel); if (N <= 0) { packed.clearQuick(); return; } packed.clearQuick(); packed.ensureStorageAllocated(N * 3); for (int i = 0; i < N; ++i) { packed.add(juce::var((double)qP0[(size_t)i])); packed.add(juce::var((double)qVel[(size_t)i])); packed.add(juce::var((double)qDurMs[(size_t)i])); } this->sendDataToGlobalCable<GlobalCables::grainpos>(juce::var(packed)); } static void onSpawnThunk(void*, float) {} static void onSpawnInfoThunk(void* user, float p0, float v01ps, float durMs) { auto* self = static_cast<Griffin_GrainOsc*>(user); if (!self) return; const int idx = self->qCount.load(std::memory_order_relaxed); if ((unsigned)idx >= (unsigned)kQueueCap) return; self->qP0[(size_t)idx] = p0; self->qVel[(size_t)idx] = v01ps; self->qDurMs[(size_t)idx] = durMs; self->qCount.store(idx + 1, std::memory_order_release); } void applyParamsAll() { for (auto& v : voices) applyParamsForVoice(v); } void applyParamsForVoice(Voice& v) { const double grainMs = juce::jlimit(1.0, 2000.0, params[kGrainSizeMs]); const double densityHz = juce::jlimit(0.1, 200.0, params[kDensityHz]); uint32_t grainSm = (uint32_t)juce::roundToInt((grainMs * 0.001) * v.sr); if (grainSm == 0) grainSm = 1; const bool lenChanged = (grainSm != v.lastGrainSm); const bool denChanged = (std::abs(densityHz - v.lastDensityHz) > 1e-12); if (lenChanged || denChanged) { v.gran.setParameters(grainSm, densityHz, 0.0); v.lastGrainSm = grainSm; v.lastDensityHz = densityHz; } ggrain::SpawnParams sp{}; sp.mainPos01 = juce::jlimit(0.0, 1.0, params[kMainPos]); sp.spray01 = juce::jlimit(0.0, 1.0, params[kSpray]); sp.sprayMode = ggrain::SprayMode::Gaussian; sp.baseLenSm = grainSm; sp.sizeRand01 = juce::jlimit(0.0, 1.0, params[kRandSize]); // Honor requested pitch exactly (no limiting). UI control is still clamped, but note+UI sum is not. const double uiPitchSt = juce::jlimit(-36.0, 36.0, params[kPitchSt]); const double noteSemis = (double)v.note - 60.0; sp.pitchSemitones = uiPitchSt + noteSemis; sp.pitchRand01 = juce::jlimit(0.0, 1.0, params[kRandPitch]); sp.reverseChance01 = juce::jlimit(0.0, 1.0, params[kReverseChance]); sp.stereoSpread01 = juce::jlimit(0.0, 1.0, params[kStereoSpread]); const int envIdx = (int)juce::jlimit(0.0, 2.0, params[kEnvMode]); sp.envMode = (envIdx == 0 ? ggrain::EnvelopeMode::RectRaisedCos : envIdx == 1 ? ggrain::EnvelopeMode::Triangle : ggrain::EnvelopeMode::Hanning); v.gran.setSpawnParams(sp); const size_t cap = v.gran.capacity(); const size_t want = (size_t)juce::roundToInt(juce::jlimit(1.0, (double)cap, params[kMaxGrains])); v.gran.setMaxActiveGrains(want); } struct SampleBuf { std::vector<float> data; double srcRate{ 44100.0 }; }; static constexpr int kQueueCap = 512; double sr{ 44100.0 }; std::array<double, kNumParams> params{}; snex::PolyData<Voice, NV> voices; std::vector<SampleBuf> pool; std::array<float, kQueueCap> qP0{}; std::array<float, kQueueCap> qVel{}; std::array<float, kQueueCap> qDurMs{}; std::atomic<int> qCount{ 0 }; std::atomic<int> seq{ 0 }; }; } -
RE: # Bug report draft: compiled network passes audio UNFILTERED inside a HardcodedMasterFX (raw node works)posted in Bug Reports
Here's a real life example of c++ modslots.
It's not minimal i'm afraid but it shows it in use.
If you'd like to see the minimal example, it's just as @ustk said, have a look at this post:
https://forum.hise.audio/topic/14270/how-do-you-set-up-external-modulation-slots-c// ==============================| Griffin Poly EQ Filter |=================================== // // File: Griffin_EQFilter_Poly.h // Node: Griffin_EQFilter_Poly // Package: Griffin DSP Essentials for HISE // Author: Griffinboy // HISE Forum: https://forum.hise.audio/user/griffinboy // Copyright: Copyright (c) 2026 Griffinboy // // Description: // Minimum-phase EQ filter with per-voice state and frame processing. // Designed for sample-accurate modulation in synthesis contexts. // Uses more CPU than the block-rate Griffin_EQFilter. // // Has Mod slots for frequency, Q, and gain. // // License: // GNU General Public License v3.0 or later (GPL-3.0-or-later). // // This file is part of Griffin DSP Essentials for HISE. // // This program is free software: you can redistribute it and/or modify it under the // terms of the GNU General Public License as published by the Free Software Foundation, // either version 3 of the License, or (at your option) any later version. // // This program is distributed in the hope that it will be useful, but WITHOUT ANY // WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A // PARTICULAR PURPOSE. See the GNU General Public License for more details. // // You should have received a copy of the GNU General Public License along with this // program. If not, see <https://www.gnu.org/licenses/>. // // ================================================================================================ #pragma once #include <algorithm> #include <cmath> #include <JuceHeader.h> #include "src/griffinboy/modules/essentials/eq_filter/eq_filter.h" namespace project { using namespace juce; using namespace hise; using namespace scriptnode; template <int NV> struct Griffin_EQFilter_Poly: public data::filter_node_base { using VoiceState = griffin::modules::essentials::eq_filter::EQFilterFrameProcessor; using PlotModel = griffin::modules::essentials::eq_filter::EQPlotModel; using Defaults = griffin::modules::essentials::eq_filter::EQFilterDefaults; PolyData<VoiceState, NV> voices; PlotModel plotModel; SimpleReadWriteLock topologyLock; double plotSampleRate = 44100.0; SNEX_NODE(Griffin_EQFilter_Poly); struct MetadataClass { SN_NODE_ID("Griffin_EQFilter_Poly"); }; static constexpr bool isModNode() { return false; }; static constexpr bool isPolyphonic() { return NV > 1; }; static constexpr bool hasTail() { return true; }; static constexpr bool isSuspendedOnSilence() { return true; }; static constexpr int getFixChannelAmount() { return 2; }; static constexpr int NumTables = 0; static constexpr int NumSliderPacks = 0; static constexpr int NumAudioFiles = 0; static constexpr int NumFilters = 1; static constexpr int NumDisplayBuffers = 0; void prepare(PrepareSpecs specs) { SimpleReadWriteLock::ScopedWriteLock sl(topologyLock); voices.prepare(specs); for (auto& voice : voices) voice.prepare(specs.sampleRate, specs.blockSize); plotModel.prepare(specs.sampleRate); plotSampleRate = specs.sampleRate > 0.0 ? specs.sampleRate : 44100.0; if (auto fd = dynamic_cast<FilterDataObject*>(this->externalData.obj)) fd->setSampleRate(plotSampleRate); sendCoefficientUpdateMessage(); voiceManager.prepare(specs); voiceManager.setActive(1.0); } void reset() { SimpleReadWriteLock::ScopedWriteLock sl(topologyLock); for (auto& voice : voices) voice.reset(); voiceManager.reset(); } void handleHiseEvent(HiseEvent& e) { voiceManager.handleHiseEvent(e); } template <typename T> void process(T& data) { if (auto sl = SimpleReadWriteLock::ScopedTryReadLock(topologyLock)) { static constexpr int NumChannels = getFixChannelAmount(); auto& fixData = data.template as<ProcessData<NumChannels>>(); auto& voice = voices.get(); auto fd = fixData.toFrameData(); while (fd.next()) voice.processFrame(fd.toSpan()); voiceManager.process(data); } } template <typename T> void processFrame(T& data) { if (auto sl = SimpleReadWriteLock::ScopedTryReadLock(topologyLock)) voices.get().processFrame(data); } int handleModulation(double& value) { ignoreUnused(value); return 0; } double getPlotValue(int getMagnitude, double freqNorm) override { if (getMagnitude == 0) return 0.0; const auto frequency = std::clamp(freqNorm, 0.0, 0.5) * plotSampleRate; return plotModel.getMagnitudeAtFrequency(frequency); } void setExternalData(const ExternalData& data, int index) { data::filter_node_base::setExternalData(data, index); ignoreUnused(index); if (auto fd = dynamic_cast<FilterDataObject*>(data.obj)) fd->setSampleRate(plotSampleRate); sendCoefficientUpdateMessage(); } void createExternalModulationInfo(OpaqueNode::ModulationProperties& info) { modulation::ParameterProperties::ConnectionList list; auto addParameterSlot = [&list](int parameterIndex) { modulation::ConnectionInfo slot; slot.connectedParameterIndex = parameterIndex; slot.modColour = HiseModulationColours::ColourId::FX; slot.connectionMode = modulation::ConnectionMode::Parameter; slot.modulationMode = modulation::ParameterMode::ScaleAdd; list.push_back(slot); }; addParameterSlot(2); addParameterSlot(3); addParameterSlot(4); info.fromConnectionList(list); info.setModulationBlockSize(Defaults::modulationBlockSize); } template <int P> void setParameter(double v) { if constexpr (P == 0) { SimpleReadWriteLock::ScopedWriteLock sl(topologyLock); const auto nextShape = (int)std::round(v); applyToVoices( [nextShape](VoiceState& filter) { filter.setType(nextShape); }); updatePlotFromFirstVoice( [this, nextShape] { plotModel.setType(nextShape); }); } else if constexpr (P == 1) { SimpleReadWriteLock::ScopedWriteLock sl(topologyLock); const auto nextSlope = (int)std::round(v); applyToVoices( [nextSlope](VoiceState& filter) { filter.setSlopeMode(nextSlope); }); updatePlotFromFirstVoice( [this, nextSlope] { plotModel.setSlopeMode(nextSlope); }); } else if constexpr (P == 2) { const auto value = (float)v; applyToVoices( [value](VoiceState& filter) { filter.setFrequencyHz(value); }); updatePlotFromFirstVoice( [this, value] { plotModel.setFrequencyHz(value); }); } else if constexpr (P == 3) { const auto value = (float)v; applyToVoices( [value](VoiceState& filter) { filter.setQ(value); }); updatePlotFromFirstVoice( [this, value] { plotModel.setQ(value); }); } else if constexpr (P == 4) { const auto value = (float)v; applyToVoices( [value](VoiceState& filter) { filter.setGainDb(value); }); updatePlotFromFirstVoice( [this, value] { plotModel.setGainDb(value); }); } } void createParameters(ParameterDataList& data) { { parameter::data p("Shape", { 0.0, 6.0, 1.0 }); StringArray names; addTypeLabels(names); p.setParameterValueNames(names); registerCallback<0>(p); p.setDefaultValue((double)Defaults::type); data.add(std::move(p)); } { parameter::data p("Slope", { 0.0, 3.0, 1.0 }); StringArray names; addSlopeLabels(names); p.setParameterValueNames(names); registerCallback<1>(p); p.setDefaultValue((double)Defaults::slopeMode); data.add(std::move(p)); } { parameter::data p("Frequency", { 20.0, 20000.0, 0.01 }); p.setSkewForCentre(1000.0); p.info.textConverter = parameter::pod::TextValueConverters::Frequency; registerCallback<2>(p); p.setDefaultValue(Defaults::frequencyHz); data.add(std::move(p)); } { parameter::data p("Q", { 0.025, 25.0, 0.001 }); p.setSkewForCentre(0.70710678); registerCallback<3>(p); p.setDefaultValue(Defaults::q); data.add(std::move(p)); } { parameter::data p("Gain", { -30.0, 30.0, 0.01 }); p.info.textConverter = parameter::pod::TextValueConverters::Decibel; registerCallback<4>(p); p.setDefaultValue(Defaults::gainDb); data.add(std::move(p)); } } private: static constexpr int getNumTypes() noexcept { return griffin::modules::essentials::eq_filter::EQFilterDesign::getNumTypes(); } template <typename Function> void applyToVoices(Function&& function) { // PolyData iteration follows HISE's poly callback. // Each active voice receives the parameter update in its own DSP state. for (auto& voice : voices) function(voice); } template <typename Function> void updatePlotFromFirstVoice(Function&& function) { // The plot is shared UI state. The first HISE voice owns graph updates // so voices do not compete for the displayed response. if (! voices.isVoiceRenderingActive() || voices.isFirst()) { function(); sendCoefficientUpdateMessage(); } } static void addTypeLabels(StringArray& names) { names.add("Lowpass"); names.add("Highpass"); names.add("Bandpass"); names.add("Notch"); names.add("Bell"); names.add("Low Shelf"); names.add("High Shelf"); } static void addSlopeLabels(StringArray& names) { names.add("12 dB/oct"); names.add("24 dB/oct"); names.add("48 dB/oct"); names.add("96 dB/oct"); } envelope::silent_killer<NV> voiceManager; }; } // namespace project -
RE: [Tutorial] How to Multiband in Scriptnode (without artefacts!)posted in Blog Entries
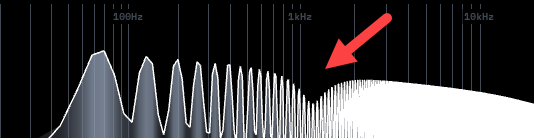
Yep! A lot of people get caught out with that.
Because it actually sounds pretty close to correct, if you use an allpass on the high band in the way that Hise's examples do.But rather than getting a notch eaten out of your spectrum, this will cause a little bump instead.
Which is subtle but it still exists. It's most noticeable when you put two crossovers near the same frequency, you get a dB or more bump in the spectrum.
-
RE: Dsp network wont compile: // <--Changed to more relevant title :)posted in Scripting
I belive this is the correct branch of Juce you need for Hise now.
You need to manually place it in the HiseDevelop juce folder before compiling Hisehttps://github.com/christophhart/JUCE_customized
As @DanH said, this is the thread to look at:
https://forum.hise.audio/topic/14184/juce-submodule-psa?_=1780482119841 -
RE: [Tutorial] How to Multiband in Scriptnode (without artefacts!)posted in Blog Entries
@dannytaurus
I fear I might have explained it badly - only after I started writing this article did I realise how difficult it was to put into words!Luckily, Chat GPT exists, and anybody who doesn't have a clue what I'm trying to explain, can hopefully ask GPT to elaborate a bit : )
-
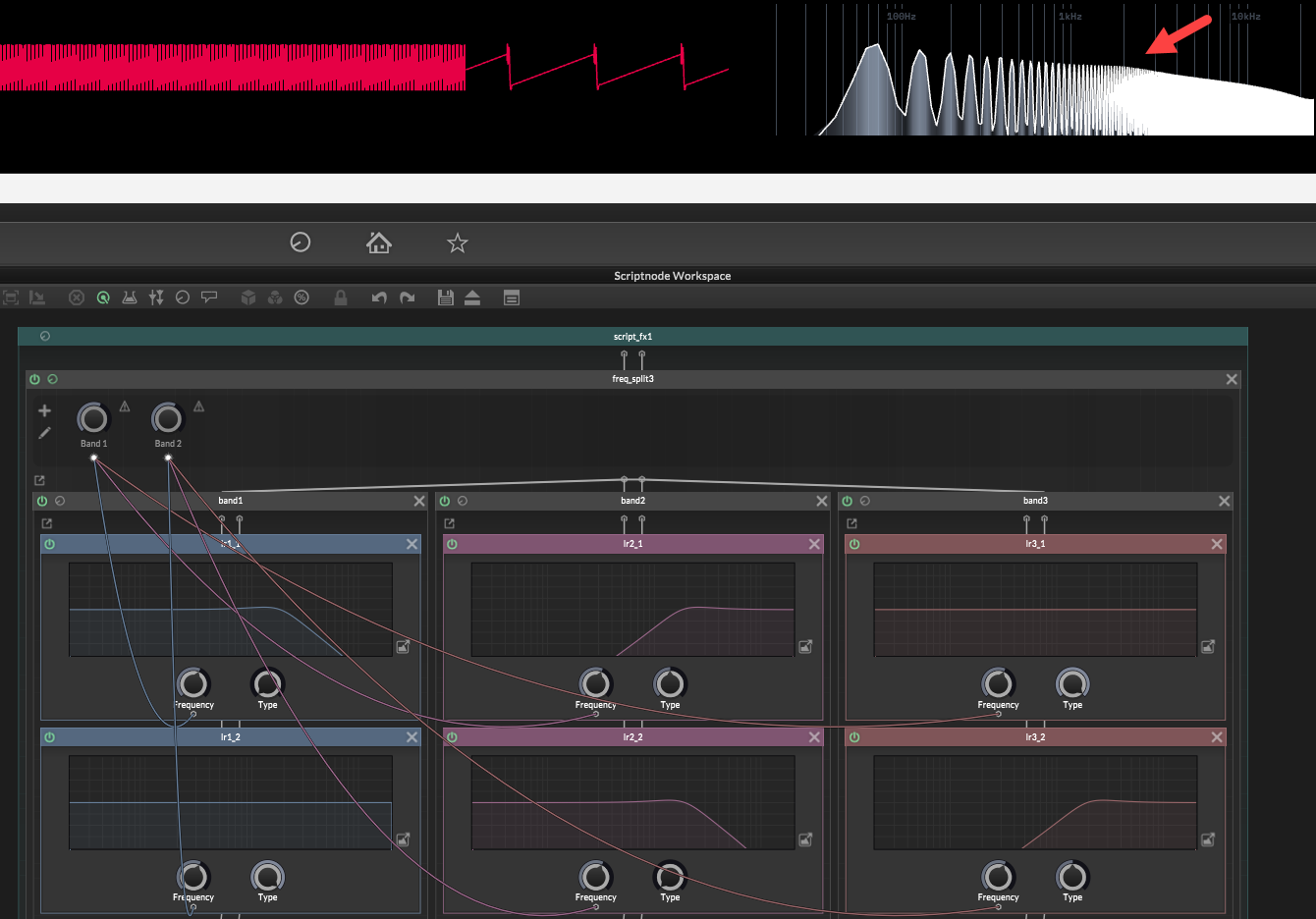
[Tutorial] How to Multiband in Scriptnode (without artefacts!)posted in Blog Entries
I’ve seen a few people try to build multiband chains in ScriptNode and run into the same problem:
The filters look like they are splitting bands correctly,
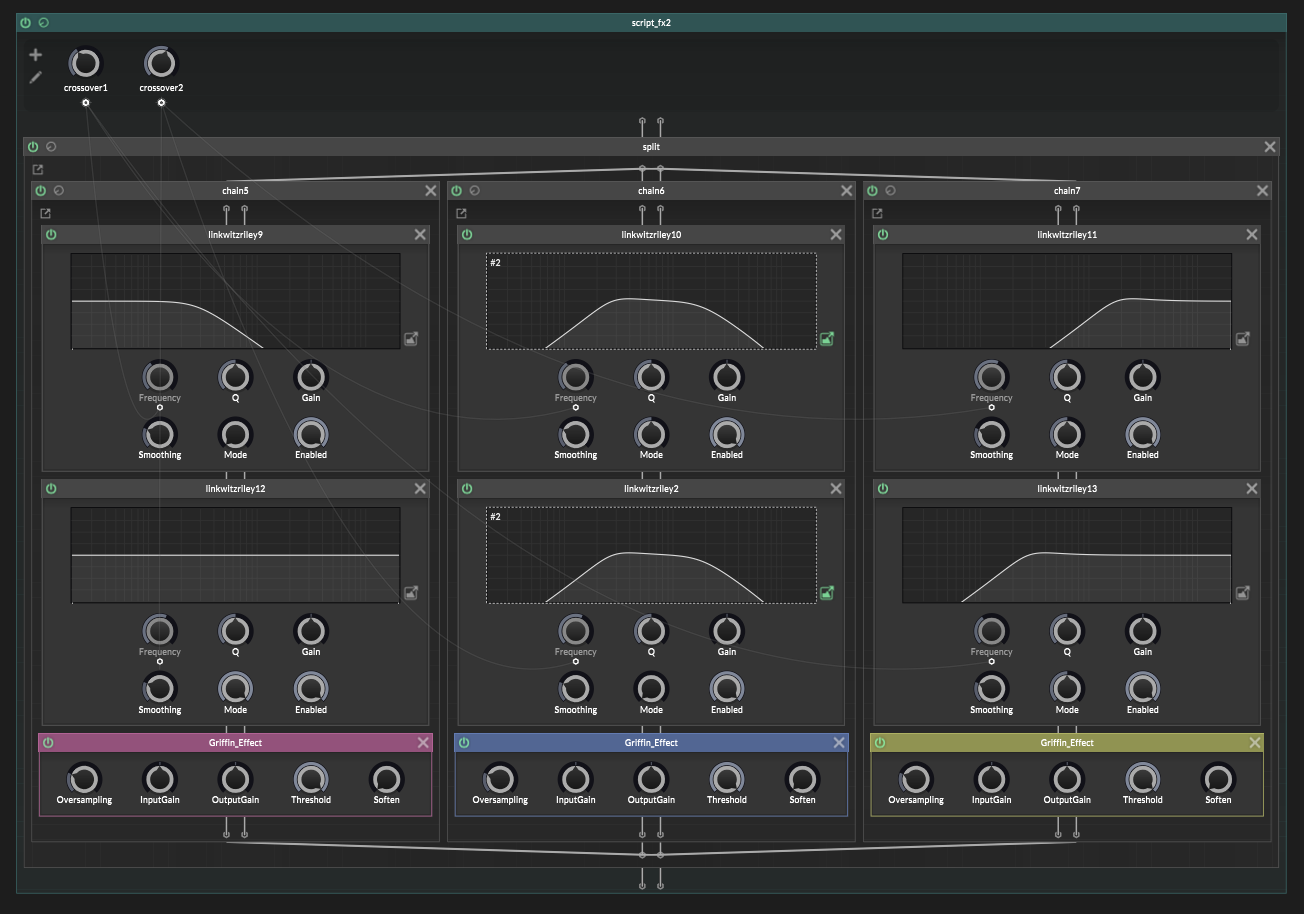
(image note: the middle band filters are a highpass node followed by a lowpass node, they share a linked filter display which is why they both look like a bandpass on the display. That's a drawing of the combined response, but it's actually a separate lowpass and highpass node)
but when you sum them back together the sound gets hollow.
The spectrum has a dip!It is phase cancellation.
I actually do have my own custom multiband node for this, that handles everything automatically, with higher quality filters that can be modulated without glitches. And I’ll be releasing that to the forum for free in the future.
But until then:
It's actually possible to make a basic splitter in Hise using stock effects.
So without further ado, lets begin : )The mistake
A multiband splitter does not work if you just:
- lowpass for the low band
- bandpass for the middle band
- highpass for the high band
- then sum everything back together
That looks logical, but the filters are not only changing volume.
They are also changing phase.
So when the bands recombine, your signals are out of phase with each other and don't add together properly. Part of the signal cancels out and you get a frequency dip.
That is the hole.
Building a perfect multiband in ScriptNode
Use Linkwitz-Riley filters for the crossover split. In HISE, that means
jdsp.jlinkwitzriley.In Linkwitz-Riley the LP and HP modes are designed to add back together cleanly when they use the same crossover frequency.
For 2 bands, it's easy.
For more than 2 bands, you also need AP mode.
That is where the annoying part begins.
The simple case: 2 bands
A 2-band splitter is just one matched crossover.
That gives you:
Low: LP 1 High: HP 1Both filters use the same crossover frequency.
Nice and clean. No phase artefacts yet.
The hard case: more than 2 bands
The 2-band split is easy because there is only one crossover.
(One side gets LP 1, the other side gets HP 1, and they are a matched pair).With 3 bands or more, it's different.
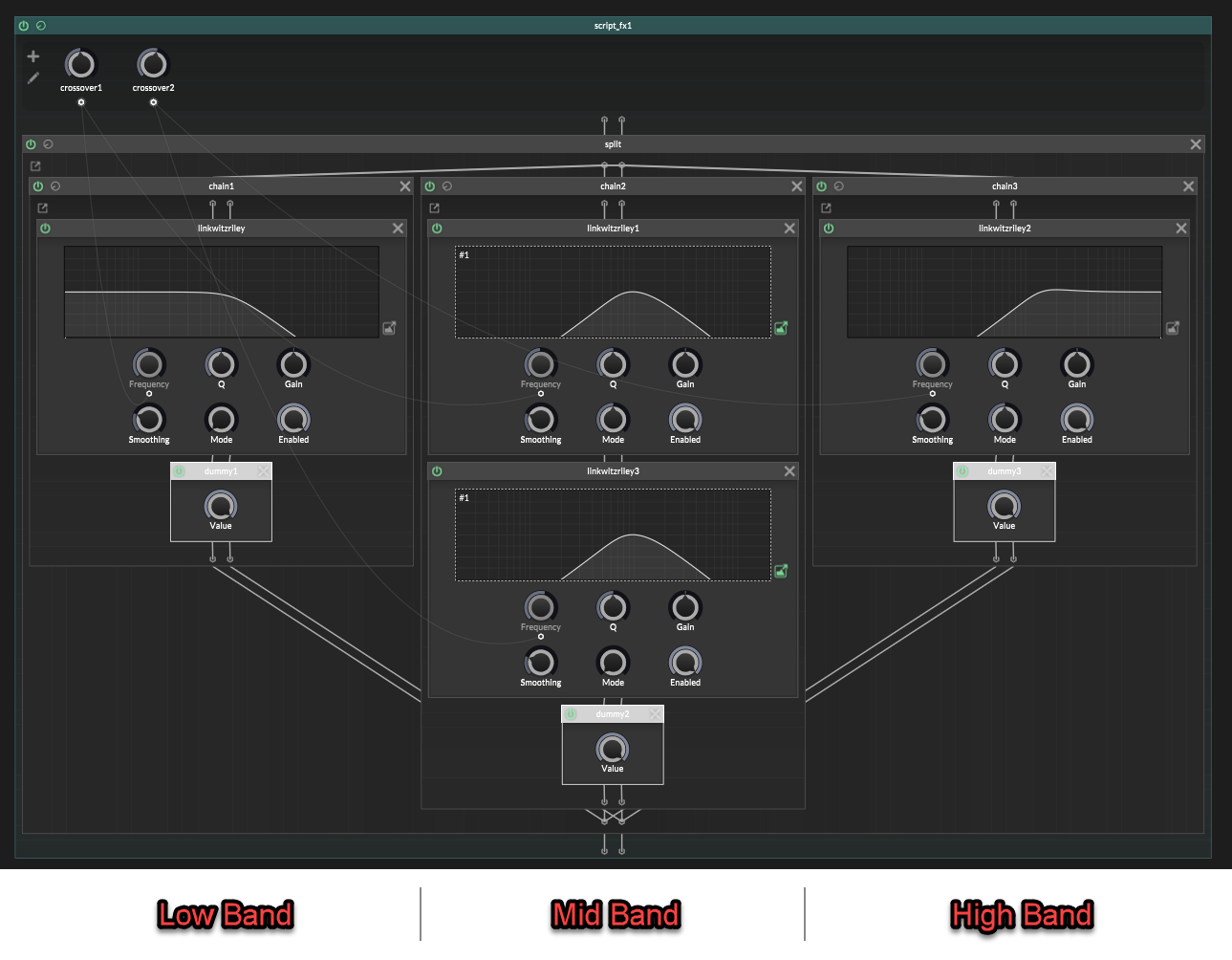
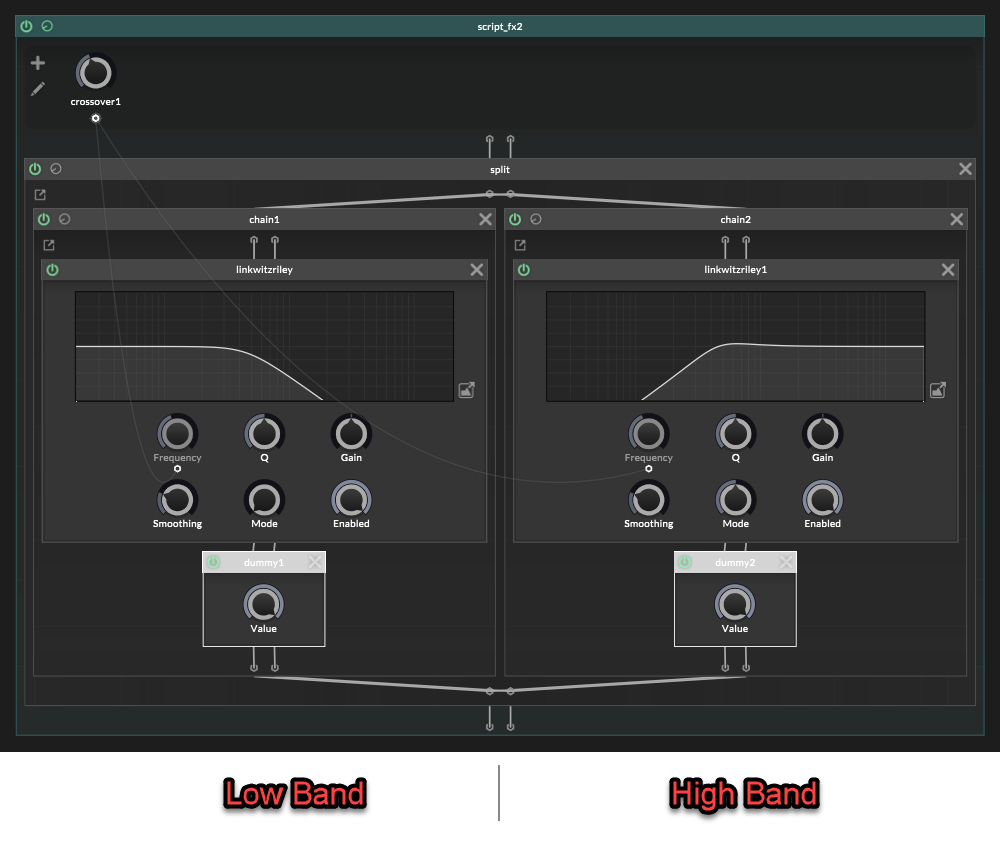
This is where the simple setup breaks.Lets use 3 bands as an example.
With 3 bands there are two crossovers: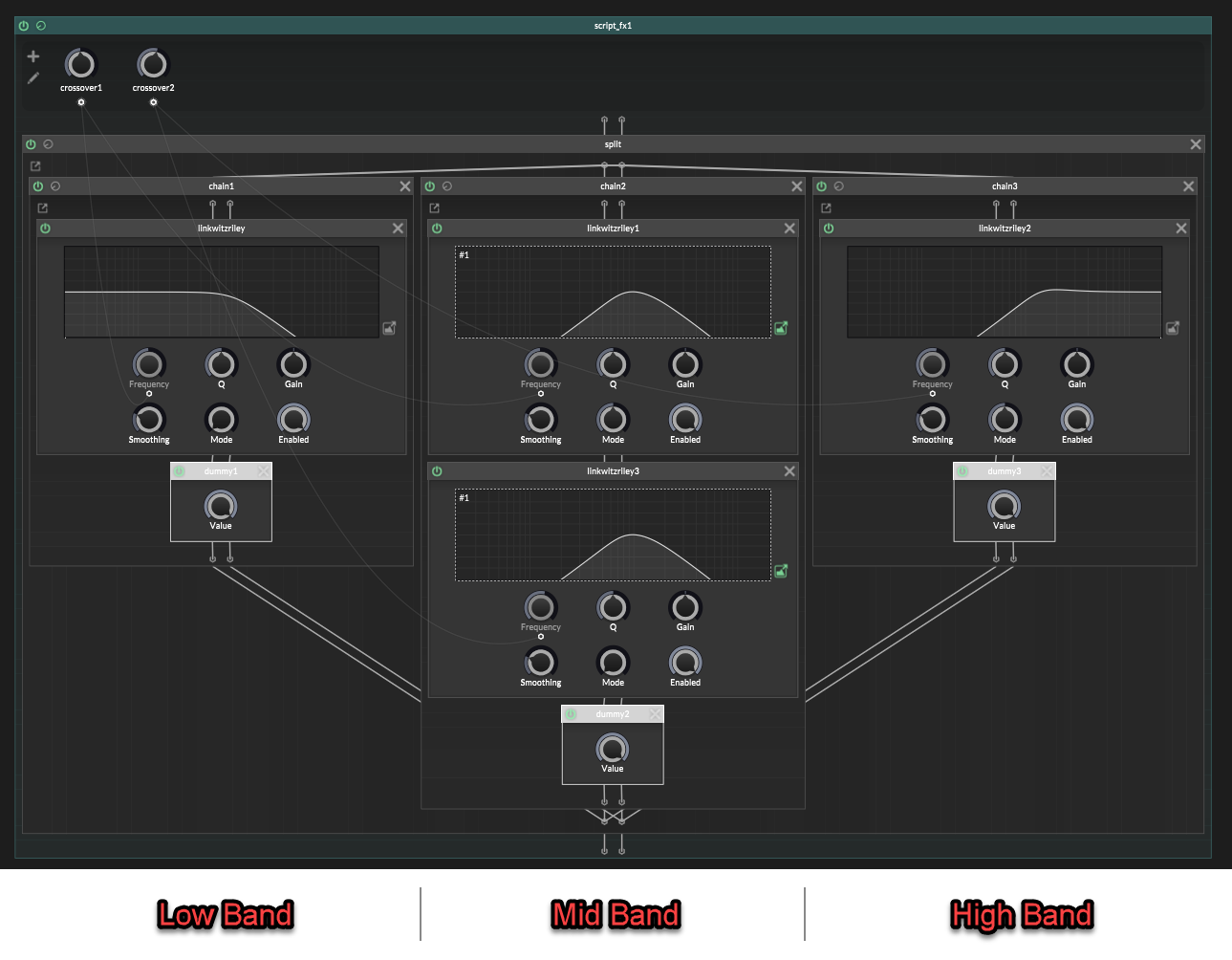
It is tempting to think this is correct:
Low: LP 1 Mid: HP 1 -> LP 2 High: HP 2That looks reasonable at first glance.
Low is lowpassed.
Mid is between the two crossovers.
High is highpassed.But the paths are not phase equivalent anymore.
Filters affect phase, so if one band gets shifted differently from the others, the bands will not line up properly when summed:
In a 3 band multiband split, we have two crossovers.
The mid band has already gone through two crossover filter stages:Mid: HP 1 -> LP 2But the low and high bands have only gone through one crossover filter stage each.
That is the mismatch.The mid band has been shaped by crossover filter 1 and crossover filter 2, so its phase has moved through both filter stages.
But In the naïve version, the high band is only:
High: HP 2That skips crossover 1 completely.
We need both crossovers to be represented.
So the high band should be:
High: HP 1 -> HP 2Not because we want to “highpass it twice” for the sound, but because the high band still needs the phase from crossover 1 and well as crossover 2.
The low band has the opposite problem.
It has crossover 1 already:
Low: LP 1But it does not have crossover 2 at all.
We do not want to filter the low band with
LP 2orHP 2, because that would change the low band itself.We only want it to carry the phase movement from crossover 2.
That is what an allpass is for in this situation:
Low: LP 1 -> AP 2Now the full 3-band layout is:
Low: LP 1 -> AP 2 Mid: HP 1 -> LP 2 High: HP 1 -> HP 2This is the correct layout to copy.
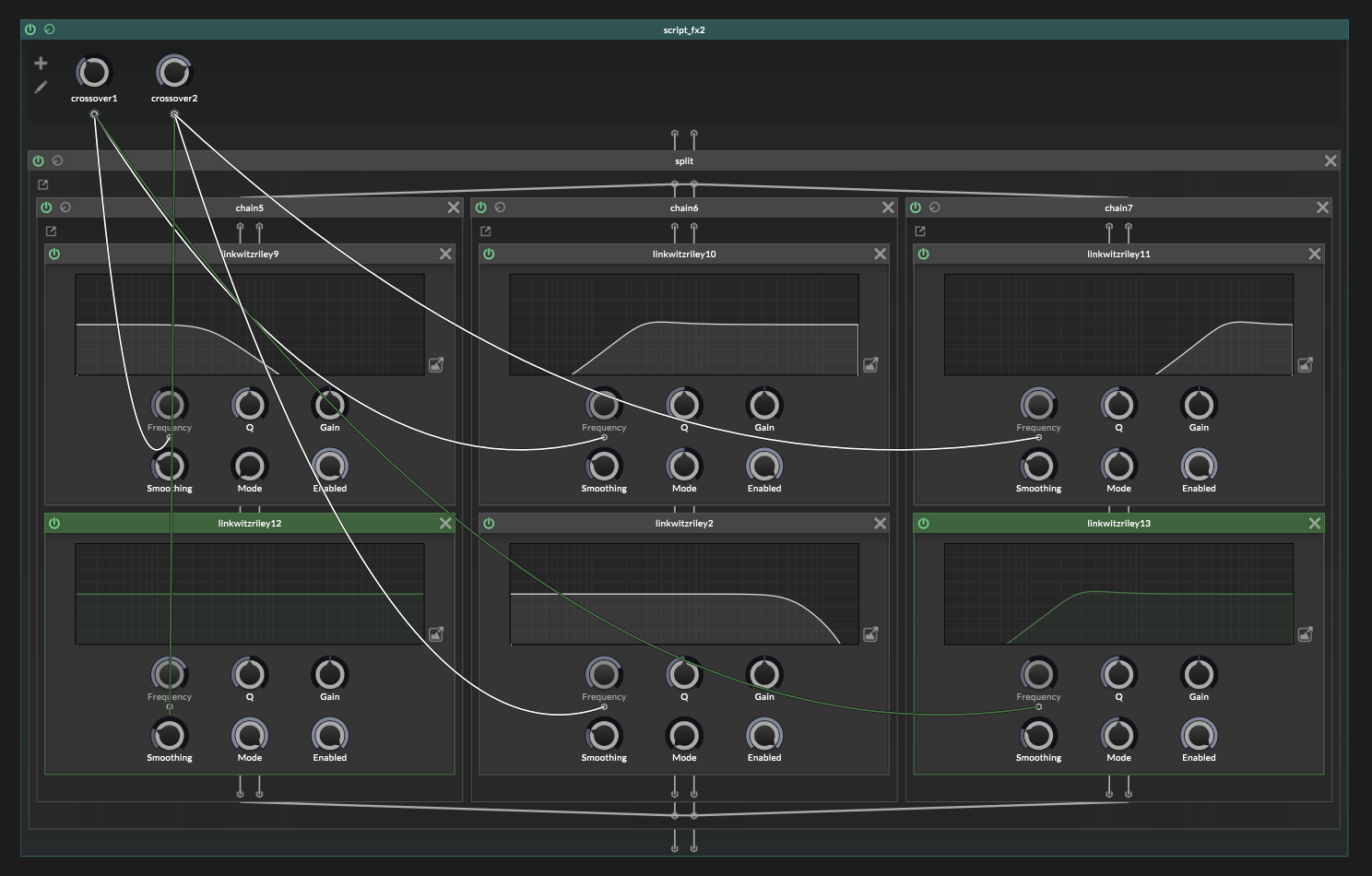
The allpass is not changing the frequency balance. It is just giving the low path the same phase movement from crossover 2, so everything adds back together properly.
No more frequency dip! : )
Add your effects after the splitter
Once the splitter is correct, add whatever effects you wanted to apply to each band, after the crossover nodes.
The generic recipe
Once you understand the 3-band version, the bigger versions are just more of the same.
The practical way to do this is to work band by band.
Each band is one branch in your
container.split.For each band, you need as many
jdsp.jlinkwitzrileyfilters as crossover frequencies.So if you want 6 bands, that means you'll have 5 crossovers, and so each branch should have 5 Linkwitz-Riley filters placed inside it.
The filter modes change depending on which band you are making.
For Band "X":
- add HP filters for every crossover before Band "X"
- add LP for the crossover at the top of Band "X"
- add AP filters for every crossover above Band "X"
The top band is the only exception.
It has no top cutoff, so it is just HP for every crossover.
Lets do an example with a 6-band splitter.
A 6 band splitter has 5 crossovers, so needs 5 filters on each band:Band 1: LP 1 -> AP 2 -> AP 3 -> AP 4 -> AP 5 Band 2: HP 1 -> LP 2 -> AP 3 -> AP 4 -> AP 5 Band 3: HP 1 -> HP 2 -> LP 3 -> AP 4 -> AP 5 Band 4: HP 1 -> HP 2 -> HP 3 -> LP 4 -> AP 5 Band 5: HP 1 -> HP 2 -> HP 3 -> HP 4 -> LP 5 Band 6: HP 1 -> HP 2 -> HP 3 -> HP 4 -> HP 5The HP filters get set to the frequency of the band above the lower crossovers.
The LP filter gets set to the frequency of the top edge of that band.
The AP filters are only phase compensation for the higher crossovers and so need those frequencies.
The rule is not hard.
But the bookkeeping is a bit fiddly.
One last trap
A Linkwitz-Riley multiband split does sum back flat, but it is not phase-identical to the untouched dry signal.
So be careful with global dry/wet mixing:
untouched dry signal + recombined multiband signalThat can create a new cancellation problem after you already fixed the splitter.
For parallel multiband effects, either mix dry/wet inside the bands, or send the dry path through the same crossover phase path.
And that's it!
A native ScriptNode multiband splitter, without the giant spectral bite taken out of it.Viola : )
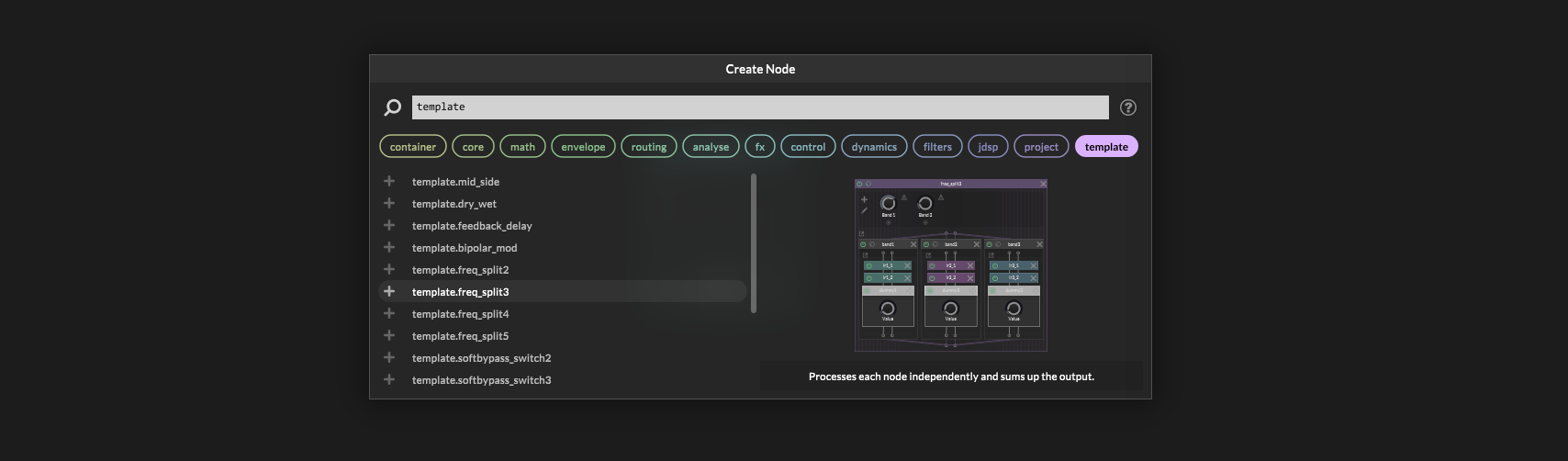
Extra note: HISE actually has some built-in templates for splitting, but they are set up wrong with mistakes, and so they don't sum together properly!
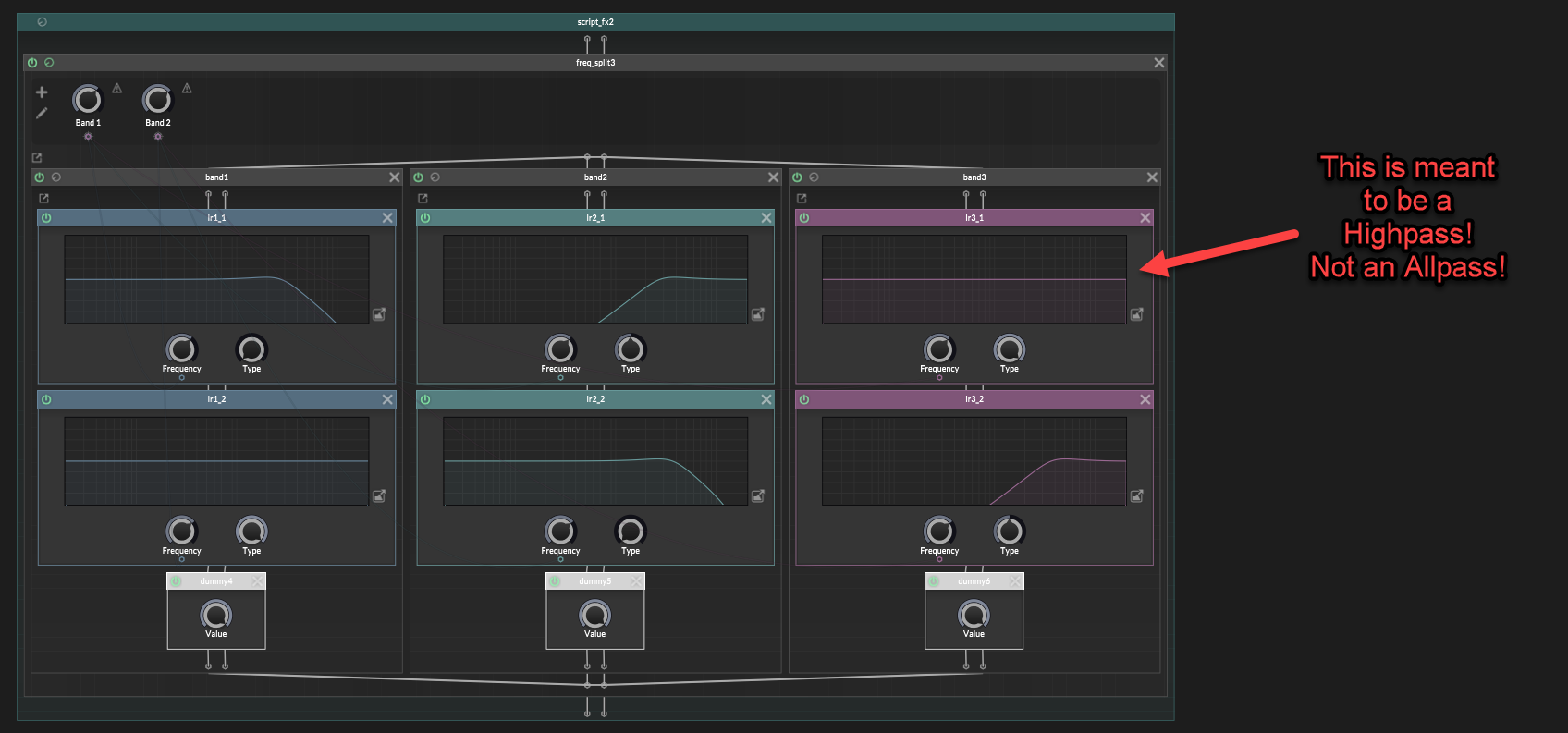
Also, Hise's Linkwitz-Riley filters aren't using modulation safe designs.
So if you modulate the crossovers you'll get some pretty bad pops and clicks. This isn't due to parameters needing smoothing. This is to do with the way the filters are written internally. -
RE: [Blog] My Favourite C++ Open Source DSP Referencesposted in Blog Entries
Yes, I'm mostly using hardcoded slots myself nowadays rather than scriptnode : )
There seem to be a few bugs still left with modulation and C++ nodes, but once those are ironed out, this is the way!
But I still make scriptnode nodes for other users who are into that workflow.
And I do think Scriptnode can be good for a fair few things, like when you need a multiband chain: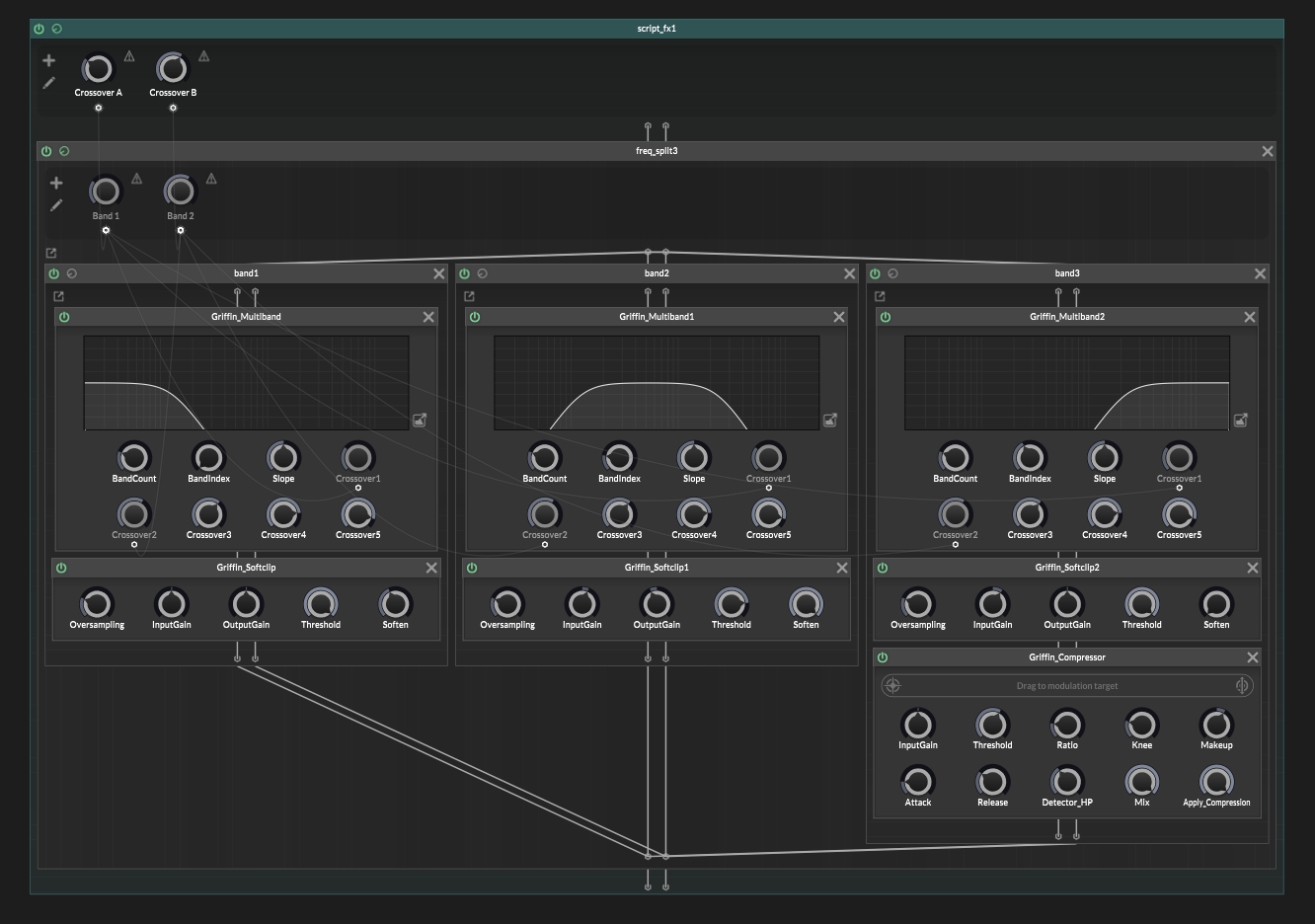
-
RE: "Error at node: chain" while 'compiling network to dll'posted in Scripting
Ah missed that! It slipped my mind somehow. thx for mentioning.
-
RE: "Error at node: chain" while 'compiling network to dll'posted in Scripting
You're looking for
Hise Develop
The insides look like this.
It's the thing you download / pull from github, and contains all the source for building Hise.