In trying to learn how to use HISE to create analogue modelled FX plugins, to start with Amp Sims, but later preamps, and compressors etc, I've done some preliminary work.
TlDr; LSTM has a large amount of training variance, therefore you should run the training recursively until you get a good model. With recent code developments by Jatin Chowdry, and Mike Oliphant, I think it is worth integrating solutions that allow NAM models, which have clear advantages in certain scenarios, while LSTM might be preferred in others.
Given that currently HISE implements RT-Neural which can load KERAS models, I started there. The easiest to use platform for generating models was the AIDA-X pipeline [https://github.com/AidaDSP/Automated-GuitarAmpModelling/tree/aidadsp_devel] (utilising docker, through talking to them on Discord I was advised that unlike what is currently documented in their GitHub you should use the aidadsp/pytorch:next branch not, aidadsp/pytorch:latest).
I found the process of training LSTM models a little frustrating compared to my previous experience with NAM. The training process is very erratic with big jumps in error rate and extremely variable end point ESR even using the exact same input output pair and model setting. I should mention though that I was attempting to train a high gain 5150 type amp here, one of the harder things to model.
To try and figure out the best model parameters I used chatGPT to create a script that would repeat the training process but randomising a number of key training parameters. I ended up doing ~600 runs. I then performed a Random Forest Regression analysis on the results of that training with best ESR as the outcome metric. I used the suggested parameters for a further 100 runs of the same input output audio pair keeping the parameters constant.
LSTM training results of randomised parameters
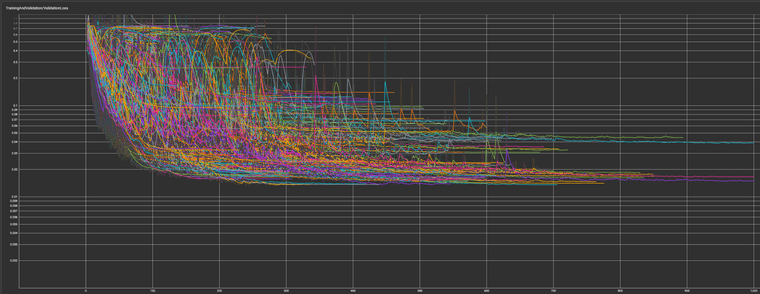
LSTM training results with Random Forest reccomend parameters
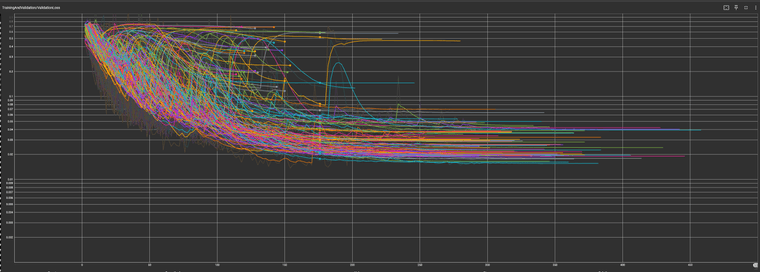
Comparison of average and IQR ESR of Random Parameters vs RF Suggested Parameters

The random forest suggested parameters did result in a lower average ESR, however it did not much reduce the amount of variation with roughly an equivalent IQR.
This is the exact same input output audio pair trained with Neural Amp Modeler (NAM). I only did 10 runs here, nor did I bother computing the IQR, because the extreme reduction in variability was pretty evident. NAM also obtained a better final ESR with a comparable model size.

Something else I discovered during my initial tests with the AIDA pipeline was that there was some of the clean signal blended into my model. This is due to the fact that in the config files a flag known as skip_con was set to "1" by default. Setting this to "0" removes the clean signal from the model. With talking to the folks from AIDA that flag is to help more accurately model things like TubeScreamers, and Klon pedals which do have some clean blend in their designs, but obviously this isn't useful for high gain amp designs, or say things like a Neve Preamp which would not have such a clean blend. skip_con will be set to 0 by default in updates to the AIDA pipeline.
There have been two recent developments, Jatin Chowdhury who is the original author of RT-Neural has created a fork of RT-Neural that can read NAM weights (https://github.com/jatinchowdhury18/RTNeural-NAM). However this fork only has the NAM functionality and can not read the KERAS models.
What might be of more interest is Mike Oliphants "NeuralAudio" (https://github.com/mikeoliphant/NeuralAudio). Mike's code is capable of reading NAM files using NAM core, as well as NAM AND KERAS models using the RT-Neural implementation. In my opinion this would be the optimal solution to incorporate into HISE.
The reason for this is flexibility. There are situations where NAM is clearly the best choice when it comes to Neural Models, especially in high saturation situations like guitar amps. However, I think LSTM has advantages in situations where time domain information is more important, or indeed on less complex signals like say component/circuit modelling where LSTM is a little lighter on CPU. Being able to use both of these approaches would open up a lot of opportunities for processing in HISE. Not just in terms of audio fx but in terms of processing instruments too.
I will publish all this info and my scripts on GitHub soon for anyone that might want to use them. The script for AIDA will be useful for people who wish to do multiple runs of training until they get a satisfactory ESR (which is my opinion is anything less than 0.02 for high gain guitar amps).