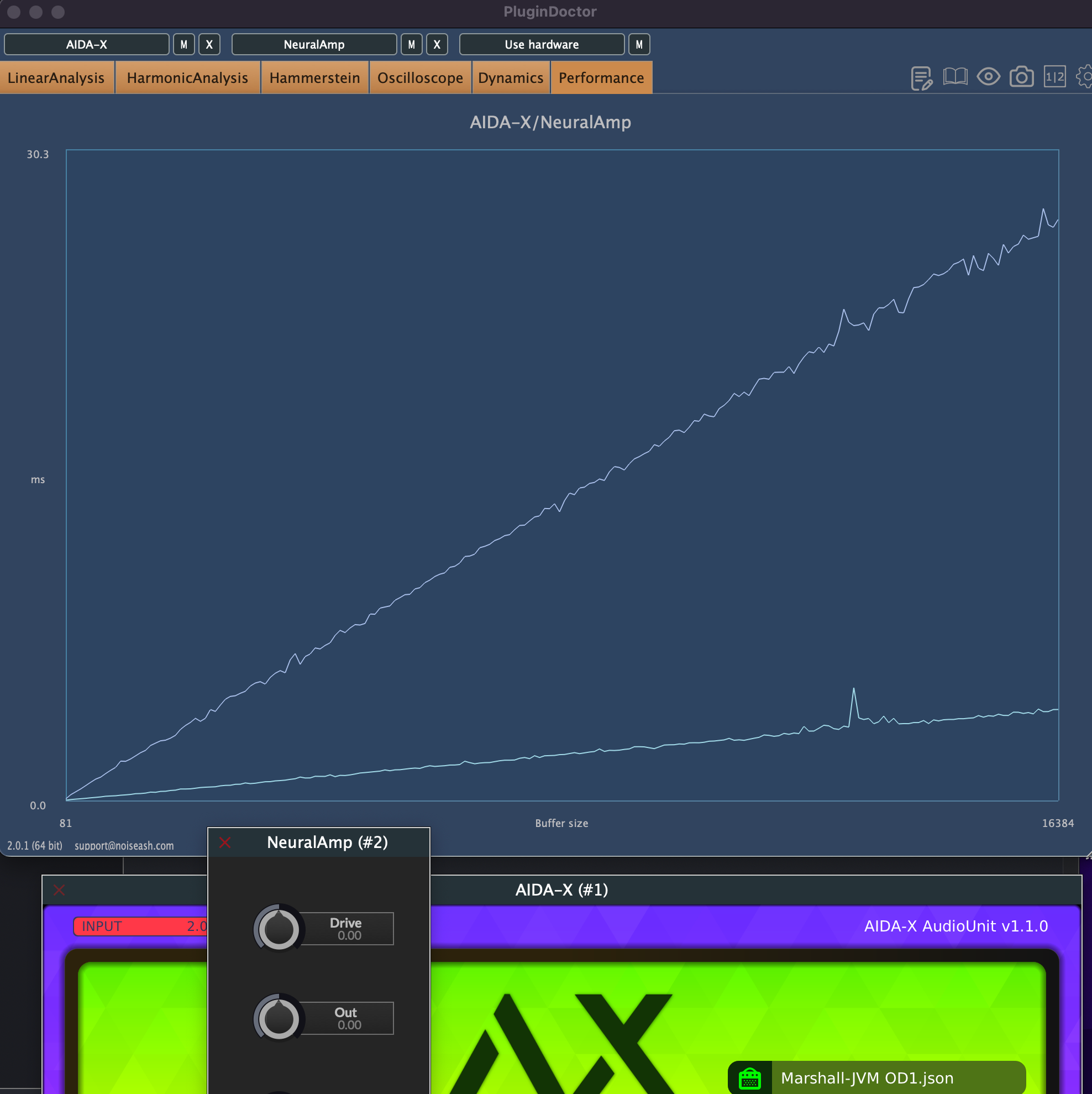
8 Times more CPU consumption on Aida-X Neural Models
-
I definitely did not oversample.
From what I've seen, Aida-X doesn't do this with multithreading.
I think this performance difference is related to the backend method used in Aida-X plugin, because it is already known that Aida-X works faster than NAM. It might be a good idea to examine Aida-X's open source method and optimize it in here.
To reduce the headroom in HISE, I compiled the Custom node and used it on HardcodedMasterFX, but it didn't make much of a difference.
This performance difference is really high. Especially when we consider the Pedal (Neural) > Amplifier (Neural) > Post FX chain, the resulting consumption will be very high.
-
Behind the scenes AIDA-X uses RTNeural, which does the heavy lifting for us.
Apparently they also use RTNeural, so not sure where that difference is coming from.
You can use different backends for RTNeural (Eigen or XIMD), HISE uses XIMD, but the difference should be in the 0% - 10% range, not 800%.
I think going forward with the neural stuff we need a collection of different models I can test against as well as a list of "competitor" implementations (like Aida-X etc). Currently I just threw in my self-baked sinus generator model I made with PyTorch, invited some guests over to celebrate that it doesn't crash and then moved on to the next shiny thing...
-
Here is a list of models that I picked. You can DOWNLOAD FROM HERE
Here is a great place to find tons of guitar amp/pedal models for free: https://tonehunt.org
Aida-X and NAM are the top used for guitar amplifiers. It would be perfect if we could open these models directly in HISE and use them with a lower CPU.
In my opinion, Aida-X is the simplest to use and train.
But NAM's library is greater and more accurate sound with higher CPU usage. -
Here's a self-trained in AIDA_X_Model_Trainer.ipynb. Ugly as hell, but it loads and compiles.
-
I can confirm the same findings anecdotally. I haven't stuck it up on a performance tester, but I have to raise my buffer size in a HISE implementation where I could run multiple models at 32 samples in AIDA-X.
Here's a bunch of models for you to test, there's a couple different sizes here.
keras-models.zip -
@Christoph-Hart NAM models, at least the standard ones, are just heavier than the average LSTM model used. A lot of the LSTM implementations have been optimised to run on a MOD Dward or Rpi. So I think 10% more CPU for NAM models sounds about right. Though there are actually smaller NAM models around that might compare more favorably. The "Lite", "Feather", and "Nano" ones. If you want any of those for testing let me know, I'll train some up for you.
-
@ccbl Is it possible the overhead is from defining the model in the script instead of loading it from a file?
-
@orange said in 8 Times more CPU consumption on Aida-X Neural Models:
I can load the Aida-X neural model in HISE
Can you pleas make a guide video or post how to use neural network or model in HISE ? i am very excited to learn the new technology but didn't get proper resources. I created a thread on this forum but no luck.
Bollywood Music Producer and Trance Producer.
-
I've done it with tensorflow using google Colab. I can help you get started if you just need to get your foot in the door.
-
@griffinboy said in 8 Times more CPU consumption on Aida-X Neural Models:
google Colab
Oh.. nice. I am at the door. Ting Tong.
 Let me know what are the required steps. because I never tried google Colab and all that you have written.
Let me know what are the required steps. because I never tried google Colab and all that you have written. -
@DabDab I haven't trained any model yet, but loading models is done like this:
- Open the Neural Sine synth example in the Snippet Browser. Delete the synth.
- Then replace the sine example with one of the models above (the models are in json format, just copy/paste).
- Then open the neural node in FX as Scriptnode, select the model then you're good to go.
When you replace the neural network, you might need to restart HISE after saving, sometimes it doesn't update.
develop Branch / XCode 13.1
macOS Monterey / M1 Max -
Something else coming back to the performance difference. I vaguely remember saying that there were optimisations pre-compiled when it came to inferencing certain architecture sizes. Given that Aida for example has a pretty specific pipeline that people use on collab, maybe they optimised that specific number of Layers and Hidden Size?
-
@ccbl yes but none of that should cause an 8x performance boost (more like 20% or so). I just need to profile it and find out where it's spending its time.
-
@Christoph-Hart cool. Well like I said, if you want any kind of models for testing, let me know. I can do either NAM-wavenet or LSTM, of any size.
-
@Christoph-Hart One thing, in the Neural Example in the docs it says this "It requires HISE to be built with the RTNeural framework to enable real time inferencing..."
I don't remember doing this explicitly when I built HISE, I just built it the standard way and it all works. I'm assuming this is just no longer a requirement? Otherwise could it explain the performance penalty?
-
@orange said in 8 Times more CPU consumption on Aida-X Neural Models:
@DabDab I haven't trained any model yet, but loading models is done like this:
- Open the Neural Sine synth example in the Snippet Browser. Delete the synth.
- Then replace the sine example with one of the models above (the models are in json format, just copy/paste).
- Then open the neural node in FX as Scriptnode, select the model then you're good to go.
When you replace the neural network, you might need to restart HISE after saving, sometimes it doesn't update.
Wow... i will give it a try. Later I will need @griffinboy help.
-
@orange I am probably doing something wrong, but when I try to make this work, HISE crashes. Here is my process:
- I copy the NN code from the Sine synth example into the interface onInit script in my project
- I replace everything in the obj declaration with the .json from one of your AIDA-X captures
- I add a scriptnode math.neural node in FX
- I select the NN obj in the dropdown
- Hise crashes.
Any thoughts?
-
@Christoph-Hart Has there been a fix for this?
-
@JulesV I pushed the preliminary work I had on my mobile rig but it‘s not usable as it is. I‘ll need to do a few more performance tests and cleanup.
-
@Christoph-Hart Thank you.
I see you also added ONNX. I'm not sure if we can open NAM models in ONNX, but it would be great to be able to load and run NAM models with performance.