Sampler Timestretching function result in high CPU (possible bug?)
-
All the Sampler Timestretching function in the voice start section seems to make the CPU really high (Windows 11, latest Develop Branch)
-
I get around 30-40% cpu from a single sampler with one sample in it for precision.
-
@Gab Does it say anything with DEBUG here?

Note that if you activate trim start to get rid of the latency, then yes you'll get a big CPU spike at the voice start, but it's not 30% here, more like 10% or so.
-
@Christoph-Hart I haven't tried it for a few weeks but I was getting similar spikes. Coupled with Unisono mode in a Synth Group and I was getting up to 600%
 Sadly I don't have confidence in it as a release ready feature yet but very happy to be proved wrong...
Sadly I don't have confidence in it as a release ready feature yet but very happy to be proved wrong...Trim Start Mode
DHPlugins / DC Breaks | Artist / Producer / DJ / Developer
https://dhplugins.com/ | https://dcbreaks.com/
London, UK -
@DanH I remember getting terrible performance out of it too - I think I posted about it. I don't see the time stretching being very useful for any real time applications because you either have significant latency or you get unusable cpu.
Edit: Here's the discussion https://forum.hise.audio/topic/7303/timestretching-pitchshifting/115?_=1728298631017
Free HISE Bootcamp Full Course for beginners.
YouTube Channel - HISE tutorials
My Patreon - More HISE tutorials -
@d-healey yeah I'm also not super pumped about how it turned out, which is a shame because it doesn't do the signalsmith library and algorithm any justice (which sounds reasonably great and is actually quite CPU efficient). It feels like we're 95% there from an effort perspective but the missing 5% makes the whole thing moot.
The problem is that you have to feed it with more or less 50ms of material until the engine produces any output and the current options that are available are to just process 50ms of audio in the first audio block when you start a voice (that's why the CPU spikes so much because you have to calculate basically 10x as much as normal) or just ignore this and get a latency of 50ms.
My best shot to solve that was to prerender the preload buffers with the current timestretching ratio (usually the preload buffers are 8192 samples long which is more or less exactly double of the latency), but since the timestretch ratio isn't static and can be even changed mid flight with tempo changes, this would require rerendering the preload buffers which would then cause spikes at this event. But now that you pushed that problem into my limited attention span again, I might have another idea:
- we prerender the first 4096 samples of the preload buffer with the current timestretch ratio. That effectively doubles the memory usage of samplers that use timestretching, but since the use case of this isn't large sample sets with thousands of round robins, it should be fine.
- As long as the timestretch ratio doesn't change, you can start a voice and bam, no latency, no CPU spike.
- If you start a voice with another timestretch ratio than requested, we will use the same logic as the lazy load mechanism, which is defer the voice start, tell the sample streaming thread to get busy and prerender the new timestretch ratio and then start the voice once that's ready.
I have to check again how fast the background thread can do this, but IIRC the latency of the lazy load mode was way below 50ms which would be a considerable improvement (and for real accurate timing you can still always enable the other mode with the CPU spikes).
-
@Christoph-Hart this is a very reasonable compromise....so sounds perfect to me.
-
@Christoph-Hart No DEBUG i'm on the release version with Faust enabled
-
@Christoph-Hart I will try that, thanks for the input!
-
@Christoph-Hart can't you stretch the loading over 10ms and get only a portion of the spike? 10ms is very manageable latency-wise
-
@aaronventure no its either synchronous (all at once) or defer and be as fast as possible (but I would expect that to be in the below 10ms range). It will still cause a CPU spike, but on the streaming thread where it won't cause drop outs and danger levels in your DAW CPU meter.
-
Alright, the results are in and it's super promising.
So basically I've ditched the idea of caching the last used timestretch ratio, I just pass it over to the streaming thread and tell it to get busy.
Now for the test setup I've added one sine wave sample, panned it full to the right and added a short noise click on the left channel. This way we can detect the latency for each timestretch start mode. Let's start with the synchronous one:
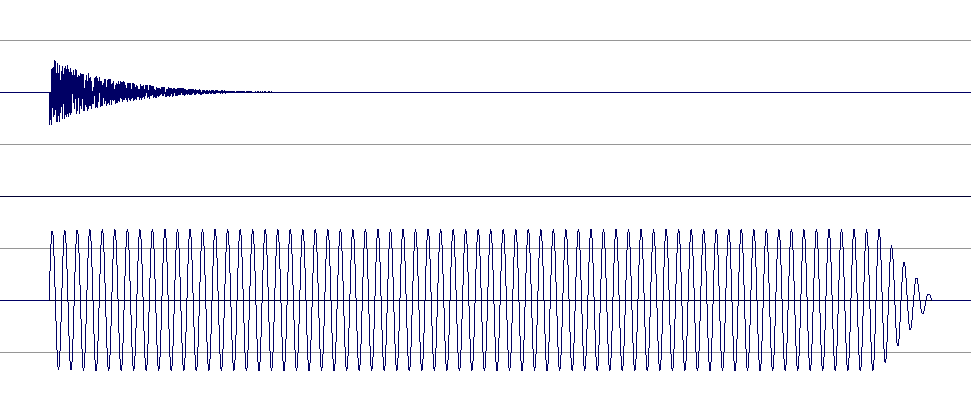
As you can see, the latency is basically zero. Good stuff, but look at the CPU graph:

So, Spikey McSpikeFace is not very convincing. Now let's take a look at the mode where it does nothing and introduces the full latency (with no CPU bump):
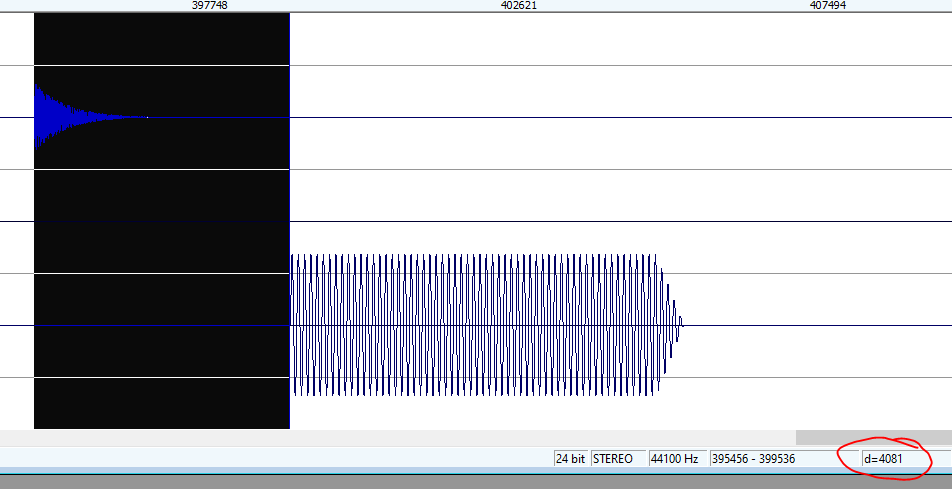
BOOOH! 4081 samples of boring silence waiting for the voice to begin, but at least we get a flat CPU curve:

OK, now HOLD ON TO YOUR PAPERS, this is the new mode:
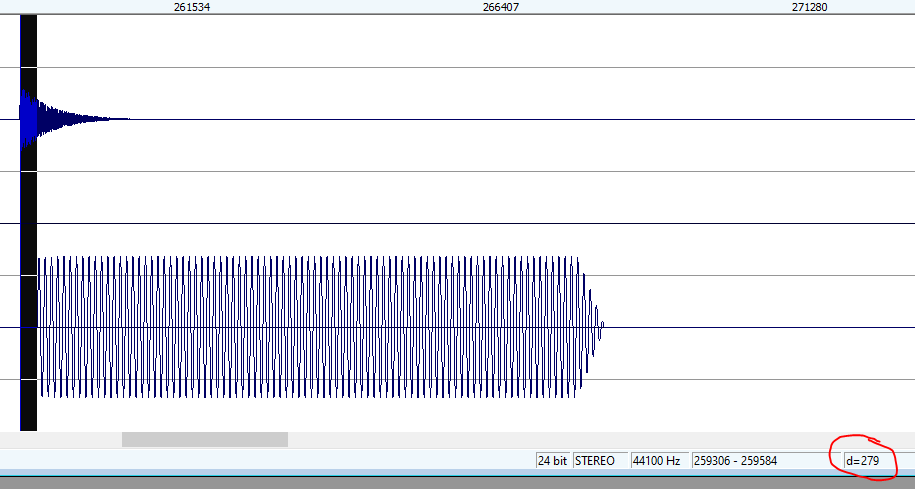
Yes, 279 samples will go by until you hear the start of the sample. That's basically 1-2 audio buffers and almost unnoticeable. When repeating this, it averages out at around 270 samples with a slight variance of 20-30 samples. Now let's take a look at the CPU curve:
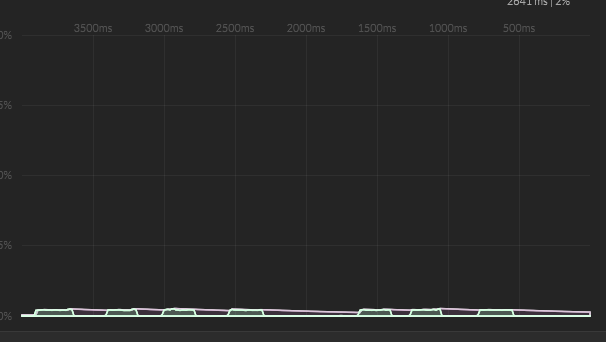
Spikes are GONE! Also the good thing is that when you're running in offline mode, it will automatically switch to the synchronous calculation so you don't get any delay when bouncing the track.
So how shall we proceed from here? I would suggest removing the entire option from the timestretching settings and set the new mode as default - you'll get a very low latency in realtime mode and when you bounce it to disk it will be sample accurate. Has anyone any objections?
-
@Christoph-Hart said in Sampler Timestretching function result in high CPU (possible bug?):
I would suggest removing the entire option from the timestretching settings and set the new mode as default
Sounds good to me, those graphics are very helpful for visualizing the situation, thanks!
-
@Christoph-Hart yeah 10ms is nothing, you can remove the entire thing.
Please write these numbers (or post the entire image set) to the docs. If someone needs real-time accuracy as well, they'll just report PDC with the transport start and the isOffline method, but knowing the correct number (270 samples) will save some time in testing.
Is the number of samples the same across sampling rates and buffer sizes?
-
@aaronventure said in Sampler Timestretching function result in high CPU (possible bug?):
Is the number of samples the same across sampling rates and buffer sizes?
No. The time it will take is samplerate agnostic and depends on how fast your OS is scheduling the background thread. Usually it's almost immediately, so you get around 1 buffer of latency because it can only be picked up by the next buffer (effectively you get less than a buffer of latency if the voice is supposed to be started mid buffer).
But maybe I still leave the option in for people who want to make sure that the sample playback is accurate?
-
@Christoph-Hart this still involves them having to report plugin delay compensation manually.
The old mode with CPU spikes is effectively useless in real products and there's no reason to have it, so you're just deciding on whether to have the option to automatically switch to it in offline, no?
If you don't do it and the new mode is always what's happening, then there is no way to actually get sample accurate playback as, as you said, there is up to 30 samples of jitter in the actual delay time.
I order to get this new instrument to sync up, devs need to add these 270 samples to the plugin delay calculation but even then it's not PERFECTLY time accurate.
If you make it so that it goes for the time accurate CPU-spikey mode in offline, then the devs who want time accuracy have to do the PDC only for non-offline playback, which is a few lines of code involving the transport handler but allows for perfect sample accuracy.
I both cases, non-stretching samplers will need delaying and in the second scenario you just bypass the delays when doing the offline render, along with setting PDC to zero.
This will be a very niche situation where it's super necessary to sync up the samplers and 5-10ms is an audible issue, but it's better to have the option of sample accurate playback and leave the spikey mode im when its rendering offline. Think some very transient-sensitive sound scenarios, like EDM kicks, where you can definitely tell that a sound is off by 270 samples. 30 samples (in real time playback) not so much but it's better to be able to say that your plugin is sample-accurate.
-
The old mode with CPU spikes is effectively useless in real products and there's no reason to have it,
Think some very transient-sensitive sound scenarios, like EDM kicks, where you can definitely tell that a sound is off by 270 samples.
Pick one :)
So my suggestion would be:
- the new default is the new one without spikes and low latency
- if you're rendering, then the default one is the one with spikes and perfect sample accuracy
- you have the option to turn on sample accurate playback in realtime to "preview" how it sounds when rendered (or if you can live with the 10% CPU spikes, if you're running in 1024 samples eg. then it shouldn't be a complete dealbreaker)
People do not have to care about option 3 (and any of this) as long as they don't use "some very transient-sensitive sound scenarios, like EDM kicks", then they can switch HQ mode on to hear what it really sounds in the end.
-
Alright, it's pushed, please have a go at it!
-
@Christoph-Hart said in Sampler Timestretching function result in high CPU (possible bug?):
Pick one :)
Heh but the PDC if submitted properly gets these kicks down do 30ms jitter in realtime, which should be fine.
@Christoph-Hart said in Sampler Timestretching function result in high CPU (possible bug?):
you have the option to turn on sample accurate playback in realtime to "preview" how it sounds when rendered (or if you can live with the 10% CPU spikes, if you're running in 1024 samples eg. then it shouldn't be a complete dealbreaker)
People do not have to care about option 3 (and any of this) as long as they don't use "some very transient-sensitive sound scenarios, like EDM kicks", then they can switch HQ mode on to hear what it really sounds in the end.Nice. Great job, man.