Simple ML neural network
-
In the homepage: https://github.com/GuitarML/Automated-GuitarAmpModelling
It says:
Using this repository requires a python environment with the 'pytorch', 'scipy', 'tensorboard' and 'numpy' packages installed.
Regarding the Neural node, parameterized FX example such as Distortion or Saturation is required which is currently only Sinus synth example is available on the snippet browser.
-
@Christoph-Hart it should be a pytorch model.
This is the training script I'm testing with. It uses RTneural as a backend as well:
https://github.com/GuitarML/Automated-GuitarAmpModellingDan Korneff - Producer / Mixer / Audio Nerd
-
@Dan-Korneff Ah I see, I think the Pytorch loader in HISE expects the output from this script:
https://github.com/jatinchowdhury18/RTNeural/blob/main/python/model_utils.py
which seems to have a different formatting.
-
parameterized FX example such as Distortion or Saturation is required which is currently only Sinus synth example is available on the snippet browser.
The parameters need to be additional inputs to the neural network. So if you have stereo processing and 3 parameters, the network needs 5 inputs and 2 outputs. The neural network will then analyze how many channels it needs depending on the processing context and use the remaining inputs as parameters.
So far is the theory but yeah, it would be good to have a model that we can use to check if it actually works :) I'm a bit out of the loop when it comes to model creation, so let's hope we find a model that uses this structure and can be loaded into HISE.
-
@Christoph-Hart said in Simple ML neural network:
I'm a bit out of the loop when it comes to model creation, so let's hope we find a model that uses this structure and can be loaded into HISE.
That'll be my homework for the day. Thanks for taking a look.
-
I realise we already hashed this discussion out, and people might be sick of it. But IMO the NAM trainer has a really intuitive GUI trainer which allows for different sized networks, at various sample rates. It also has a very defined output model format, which seems to be a sticking point with RTNeural.
Given the existence of the core C++ library https://github.com/sdatkinson/NeuralAmpModelerCore
Might it be easier to implement this instead, given many people want to use ML Networks for non-linnear processing for the most part?
-
I'll just leave these here:
https://intro2ddsp.github.io/intro.html
https://github.com/aisynth/diffmoog
https://archives.ismir.net/ismir2021/paper/000053.pdf
https://csteinmetz1.github.io/tcn-audio-effects/
I'm convinced Parameter Inference and TCNs will be the future of audio plug-ins. CNN's will take over circuit modelling as the next fad. Training NN so we can map weights to params to make any sound source will take over. Just have a look at Synth Plant 2.
Having access to trained models from PyTorch in HISE would be awesome. A few VSTs devs are using ONNX Runtime in the cloud to store the weights and the VST calls back to perform the inferences.
P
-
@ccbl for instance, how I plan to use HISE is to create plugins where I use a NN to model various non-linear components such as transformers, tubes, fet preamps etc, and then use the regular DSP in between. I'm just a hobbiest who plans to release everything FOSS though, so I'll have to wait and see what you much more clever folks come up with.
-
I realise we already hashed this discussion out, and people might be sick of it. But IMO the NAM trainer has a really intuitive GUI trainer which allows for different sized networks, at various sample rates.
The current state is that I will not add another neural network engine to HISE because of bloat but try to add compatibility of NAM files to RTNeural as suggested in this issue:
https://github.com/jatinchowdhury18/RTNeural/issues/143
There seems to be some motivation by other developers to make this happen but it‘s not my best area of expertise and I have a few other priorities at the moment.
-
@Dan-Korneff said in Simple ML neural network:
@Christoph-Hart it should be a pytorch model.
This is the training script I'm testing with. It uses RTneural as a backend as well:
https://github.com/GuitarML/Automated-GuitarAmpModellingHave you tried running it through this script?
https://github.com/AidaDSP/Automated-GuitarAmpModelling/blob/next/simple_modelToKeras.py
-
@Christoph-Hart I just read the thread and found the link. Gonna give this a go first thing this morning.
-
@Christoph-Hart
https://github.com/AidaDSP/Automated-GuitarAmpModellingThere is already a script in Automated-GuitarAmpModelling named modelToKeras.
"a way to export models generated here in a format compatible with RTNeural"I'll give both a try and report back.
I'm seeing that there is also a script to convert NAM dataset.
"NAM Dataset
Since I've received a bunch of request from the NAM community, I leave some infos here. Since the NAM models at the moment are not compatible with the inference engine used by rt-neural-generic (RTNeural), you can't use them with our plugin directly. But you can still use our training script and the NAM Dataset, so that you will be able to use the amplifiers that you are using on NAM with our plugin. In the end, training is 10mins on a Laptop with CUDA." -
Learning curve is high on this one.
I've written a config script, prepared the audio files into a dataset, trained the model with dist_model_recnet.ph.
The model_utils.py script complained about how output_shape was being accessed, so I made a little tweak there.
In the end, it was able to convert the model to keras, but the layer dimensions are exporting as null.
Time for more beer and researchDan Korneff - Producer / Mixer / Audio Nerd
-
@Dan-Korneff yeah I tried to write the wavenet layer today for RTNeural, by porting it over from the NAM codebase, but I don't know either framework (or anything about writing inference engines lol), so it wasn't very fruitful.
Let me know if you get somewhere then we'll try to load it into the HISE neural engine.
-
@Dan-Korneff DId you have any luck running the colab for training? I upload input.wav and target.wav and get an error
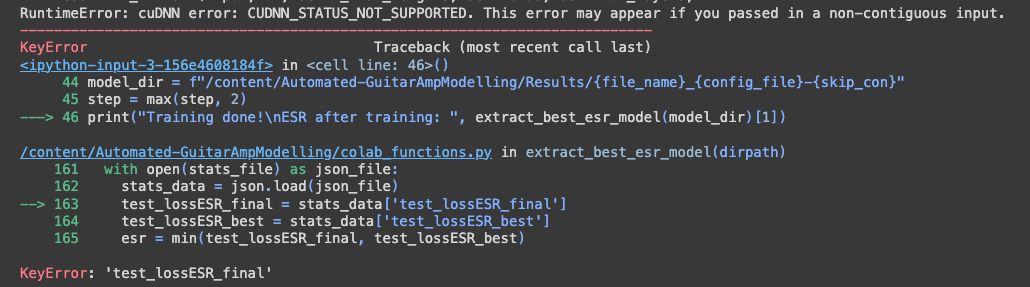
-
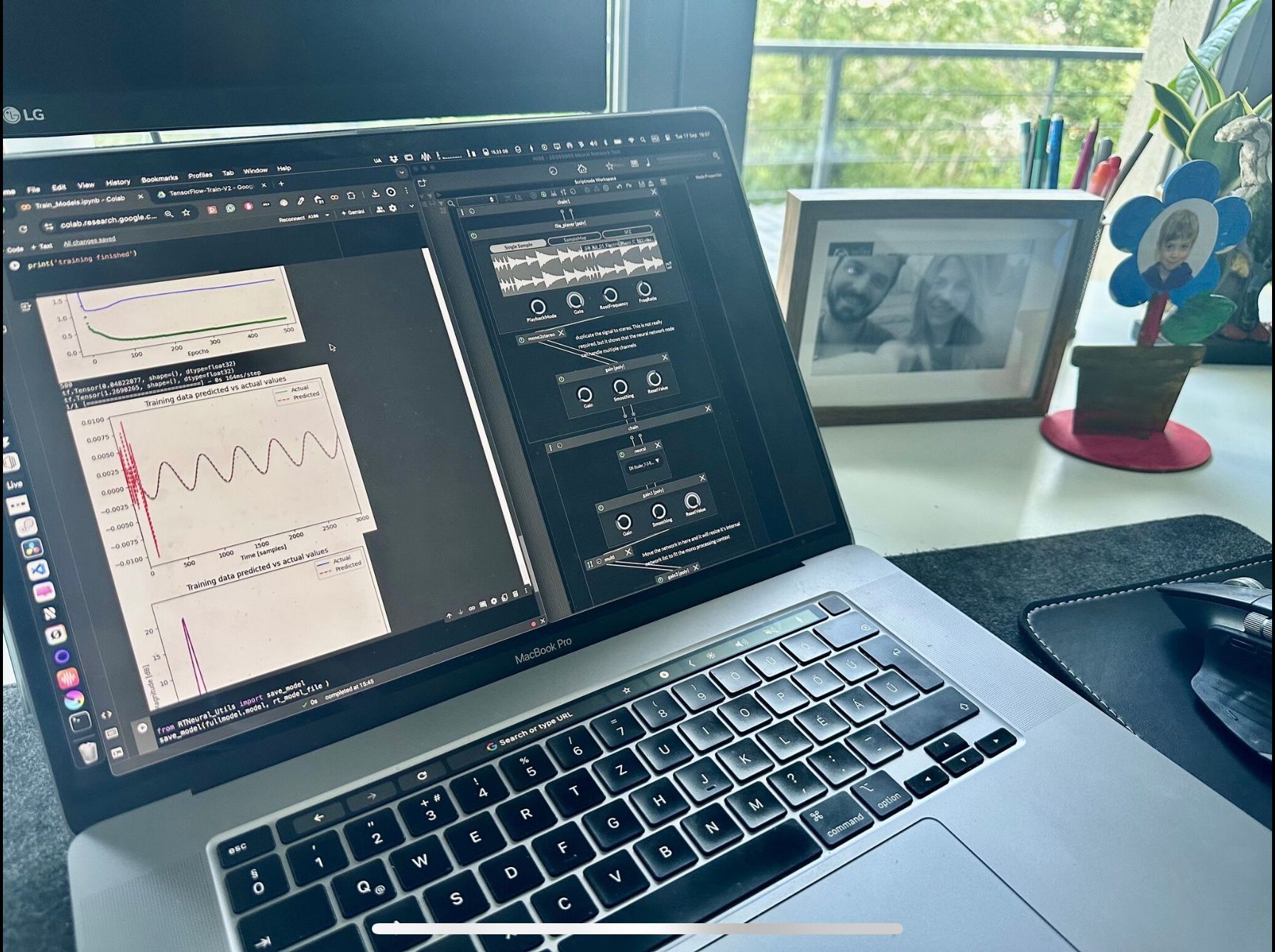
I don't know if it helps, but Karanyi Sounds (uses HISE) also does machine learning using HISE Neural Network with colab, they shared this photo today.
As I see, if this Neural implementation is done very well, it will be really popular among developers. Lots of people would love to use this latest technology in their software.
-
@Christoph-Hart It seems like so many projects are abandoned, even if it's relatively new. Still researching
-
@aaronventure The tech is evolving so much that the scripts on google collab break just about every time there is an update. I got the google collab script to work for Proteus, but moved to local processing cause my GPU is better than the ones provided by google.
-
@resonant Invite them to the conversation
Dan Korneff - Producer / Mixer / Audio Nerd
-
@Dan-Korneff In this instance the dataset refers to the input output audio pairs that NAM uses for it's training, not the resulting model. Basically they're saying they added info in their training script that can detect the NAM audio pairs and train and Aida-X model based on those.