Normalizing Audio in Convolution Node?
-
Hey!
How do I normalize audio that is entered into the convolution node? Is it possible to do so?
Thanks!
-
@Casmat normalising requires you to look at all of the audio in the track and identify the peak value...cant do that to a real-time fx like convolution....
HISE Development for hire.
www.channelrobot.com -
@Lindon i was hoping to do the detection while the sample file is "loading" into the convolution. Thought of getting the samplefile from the node itself and analyze that with some scripting, but cant seem to work out how. I'm trying to find a way to compensate for varying convolution sample volumes a user could import.. any ideas?
i make music
-
@Casmat have you tried using the file_analyser node?
-
@Casmat said in Normalizing Audio in Convolution Node?:
@Lindon i was hoping to do the detection while the sample file is "loading" into the convolution. Thought of getting the samplefile from the node itself and analyze that with some scripting, but cant seem to work out how. I'm trying to find a way to compensate for varying convolution sample volumes a user could import.. any ideas?
attach a gain control to let the user set the gain.
HISE Development for hire.
www.channelrobot.com -
Like @alhug said, the file analyser node is what you need.
HiseSnippet 1495.3oc0X8zaaTDEeVmLND2Vfp1BWmKHbjJF6RnTARTm3jzZAN0pNDUNElr6X6Qd2YV1c1jXPbhK8Fm6M9HvUt0u.bpeQ3a.7d6t16t0tINVsEgsj0Nu4My768989yrtaf1VDFpCHVqevXeAw5pzdiUlgsFxkJR6cHVuKsCOzHBXIh1drOOLT3PrrV4An.q0WkD+4uu+1bWtxVjIhPNTKsEeqzSZxj1s42Hcc2i6HNP5kS6Ma11VqZoc0Q.dVgVm3ysGwGH1mipUhRrJuqiznC5Y3FQHny1Zmw8FpOUkn+gxP4wtBbPCROXiRDSZMT55zchsFRHVq1MyxWIwxuIsizQNUdlG38imfksh79.qRmGjZbIfjUNHsZBjtNsmcfz2jMChmqPaq.BoOGb04gRhtDqmSaoAETlZd7Qh8BfASWP06Vu9sYvOa7U8iT1FoVwzp80FwiTU2nxOWY8J+RE1KOU+9ycN7XBztthf4NMxtAm2Bqph7NVDba1Ib2HwTEAyunOs7h4SsSr5bJpUsURyi7Eoi2S65f9J74YY.RpaCd56ZuC2vQRIUFnmuHvHQ3Xsi3DHpNghVmtiHbjQ6Cw0yvePji1IxkaJFNg4MoS.9iBbHRTpPoYb97pKQLV8yMFaQg30ockF6gyGiklCFAO0aBLllYdM5t86KrMY.bU5dOYYSCqu3ogzjyuRZZHbl3ge0zgr8dRiBfX+Hushbj58jtHFnVVf4LIq7ozrL.+.gOOPbftqKeb0Ptmuq3w.vuM6XWs8ndxeRLaZieBt1F0np8PtRIbCWlrqxulpXQdrNxHUC5vMAxy.6Er+dPsaaQqTzg9fRXhUx353XLXomP4DO3efOoS1XpCClrwjIykStuvbpNXTLGk9LXKIDRXrS9n9m0frkqq9zVZOeYZnKPLwx5pcG6OTqj1nnDMlfzs7zQvgjB2GxCOfKcwX8CEAgwaxZz50fuPb99ZGv4P2iaCNwwc4lgXBCV7AhNEA0rmFkV.WEBTfsXRetDOB.GOzLi6xsRtpMIAj3HHcqTxt1N7PbVatK4PjaQfRv8DUmlhOT0qgv5DsaTrin.huEsuzEZJDVKuJKKHwofX3ylT0LWZP9QPhaaki3rIa3tP.pCTQNdYoLdGoJ0nRzoC+rBiIc4Av8APniV6zQPrP1RypKks7r5o8LBeLGqfrQhSSbP4khNwxP8ZifLytPtzGcyeq4k6nqP6FHbDPQBxL69Eb7e+ym0xgbqhG+u+rm8myd7Oevebql3wC81fRSPF9k9z2r4Lm9SewhY7M+Uu+J13Wi9PYqHCYlsg7lmyuFsSjqQZFFH3Nyw5yki8dXhj3Hth6NNDfTgrrOLtt.TLtVQkVv7rlzdBCyLTFxLZVWAeDiqbXQgBPnfAMNfeb0FFOLVPtTYlJFhqdtkRJiM+mFZWlhm.39l11+.dv.gIL8dPJgcRA03RfscvRQ1bnUwQhy7CxXEbl0nIa5+UEFxyPEPYA54lSombZrfbyCnR0IfuL1wO.J4ypdJDvv3.szWLHhG3vB0vrbC6Gi.ZLTN.n+PliV8wFrQ+orH+Md4p8klghZkih9H3P8iLrulA8hZvtOqZiZ0YeZrvMXeIK9g3qPkeOVCti5wQCx0rXwo3qD2BA1LwqhgKTO1JWt4ZKetITo5UlaN4fmYq2Jxn8fR0NS6GlF.j2FJv+2Hi+mpvBR+evj8DyLcD1xig66T4h5cWLga832D3NNaeYx4JSwfshbQ43M5+CTQJ5KvBH8DHpM3k+6EtfKfTpvEPJX5qb9l98lSuw60bg5MV3VA.du.K+0vUDlON9garyKteRrcOOsFZQLaW5Ma9V3NBWk9XQnv7JhCJVSdasdjGO9J7K2aX+13EN731A5iRqKfASuSrDHnRE+2PsNsCNl0fbRZ2G7MCHdRG4Q113ql9IMHj4ul6rDq4yVh0r4RrlOeIVycWh07EKwZt24tF7emKMsCKUBB5taxEGr1Ug80iqlP9WbbZh+C -
@Christoph-Hart wow.. hise sure is amazing.. as with you @Christoph-Hart and @alhug and @Lindon! Much thanks!
-
@Christoph-Hart what a great tool and thanks for the example. if file_analyser could also do LUFS or RMS that would be amazing. Analysing a longer audio file for true peak, like a noise layer sample for example, is not that useful.
-
@alhug Couldn't you do it with a snex or faust node, just store the peak values over time and root the mean of the squares? I'm asking, I have no idea myself, I've yet to dive into snex/faust.
-
@Christoph-Hart Doesn't this just analyse the impulse response volume and not the audio going in and coming out?
-
Anybody tried this?
-
@d-healey If you're doing 100% wet, it's one and the same, no?
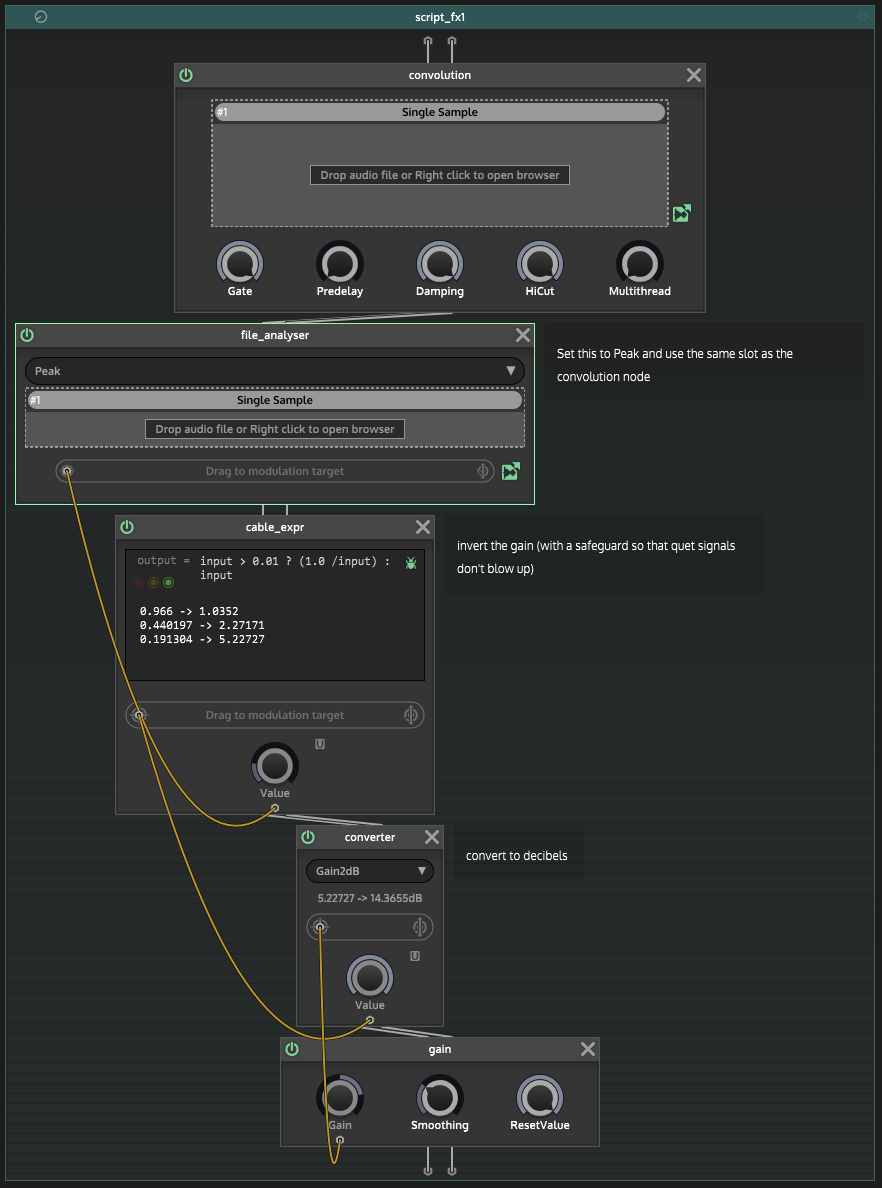
If you want to do it for any other effect, you have to use the Peak node. Here I have the filter in front of the peak node, and if you disable peak, cable_expr and converter, you can hear it behaving as you would expect from a filter, the audio being barely audible as you play higher notes.
But once you enable these, they will normalize it back up. I extended Chris' safeguard range because these filtered signals get very, very quiet. Safeguard strictness is in how small the float in the expression is (original from Chris is 0.01, I further divided that by 1000).
If you remove the filter, I'm confident you can pack this whole thing in and use it as a node in and of itself, like a normalization node.
The "1.0/input" in the expression determines what value it's normalizing to. So if you need it to be quieter, put in another float, like 0.5/input.
HiseSnippet 1800.3oc2Y8zaaTDEe13LIMosnVZKvEjFohDtRkPraosBjvN+ysQfSLwgzxovjcGaOx6NyxtylDWDmfC8Fm6M9HvUtkO.EoJ0qb.9DP3S.7lcW6cWGGGGSaoEWopcduYl2u2+mYRMOoIy2W5gLlYyNtLjw4v06HTsVpEkKPqtLx3MvUo9JlGIhzhcbo99LKjgQt6pIXLyjnveGVZQpMUXxRHgPaI4lrOm6vUITqU9y311UnVrM4Nol8MKupoTrjzVF.3IGddjK0rMsIaMpdZSfQFSshEWI8pqnJlOxXxEkVcp2RtmHZ9aw846XyzCJfpCaTD4JRaKMh0TQK0haaUqqd6iPF3ZIVgbQVgKiqxs38nmXMtPHCRxJRaOLlHK7xkAdERCu4SAuA.IiTPZxHHcQbcSOtqJgiFOmEup.bNMnfYOMThlKx3.7RRXBB0bNz1rJdvfdKH+sle9qSf+6ZeRi.gohKEDoXMohstH+0l8amclY+tYI8ypQiAxSKFOosMyafr0dZugsv7h.mcXdWmrK0Nf0ahf5m0lhOdaZZWtYjVmZhRwpBtZcWl33BDPwlJ3qub0koJp1QDSClmKySw0PvXY1tPTcjaYF7xL+1JoKDWeDeFDsHsBroprgP57lXFfMHieS6bD9bUmz4UO2hqFUHdQbMtxr0fw3DC.ifk5EAFiyFOOdkFMXlpD.NItxCdIj5gij+rwodfL0B+bwCIUdPgLfXs.mEBr3xJb6vPUCCPc5lI9HbRTuqGyk5w1TVyl1IuO0w0lsA.7qS1wVZ1tN+grilp3FgqE0yHuYKpPvr8GmLpoFYSUgg6o1PFn3hlUoJO99f9B5ecn1sIaoXzosASnSrhFOudrNXoNSXEN3ugewLKzyfALKzkYpbx0Xp8jdsC8QweiLlNxg3GZj2tw9EPKXaK2aIoiKONzEbLgzpIs631RJ3lZRQynKRWvQF.BIFt2i5uIkaqi02h44GtISimeN3en5A9PIDq0E0gUG1rSG7slzB9BWgZBF1N0npV5jHcQHHhk4MmYuH2LXMSvCrEc68EYk.H5nU8vNe4RUAJJHUOBRAmHZWW0eKMWSpMZKs+VCdjdOC6vEiO8TwX+cafxfzyiavsglB9yoYMtfRyBhi2uakyJQ6YxmZrJrX6202tBDdZAMlCWfd+P0ndPq93UMUuQv2U4hX0J4zBUo6mk1idV45JlqN8Icoo5sY6EouwTK+8N+ZontmU7XeS.3G6f5sU+4CNj+t+1sKiFh7Keia7rR8I+CdxSt5nIezU+qmFJ+b3u.0mZcXIzv06hGbD8FUbDkqd60xcpvVP8KZD5DDMBcTQeXoQRze8kV9Ywl75NRopET2Hi7K+GO7GJMFx+BCP0ALMDUupNW3EkpOLQOCdEAEprZM.edpDzovtLZ6rYnmEpk3wlKjwoH+bxL4mIsy2j50jo7iOeifYFUnLrL1pV5xIlZftMaeWuDCilyz3Hr2ex9xbeWnW1hAPi5nb9LTFdpebo9zY+oMHYPSFyxkCKwB85lK0LFQ6ycwbwtfsgnZwHMgzAR983pVDJwm1f0Lf5YQ7k.Wph.kHTDedSA01mXIEuuR2ndORf605ux7D8UYdJ3.3Iwa4Ag5FnHeJA5k.+JPJQxWXt4IeXH8qQ9XR3GgmBJ81LMbLycBZlp19n6M0AOgpJ63blYp6ZjJSX5mqEA5kIzUvGYqWHPIcfikX0q8UbLPZcHSHvkRBA5MgQLB3s5tmDkjXwL46.GYY1SpUaeEPBqjVzZwSS50TXc7VVeQbI4WUbEGV5XcEwneP0mZ1+KDbB0mlHS8oLpdtgq52Y.cAuS+sB9oG+3eozouKXVM+T2Wn7ONZ33DaIFdHmSP9e0.rCf6dTj+AM+4qTNp95FLel5XRIyVVdQorsCM7T3+quj7UhXdV78o6xBe0ovSHekvwMjdNj6xfCOquZZgg7tSOcTe2I2Q9cmV2TAPXSOpv2U5yJjdm6iWwz7VloBDYmdDoLyRqdU.0K07NS4tDKllXMpHylAiyrSU0W6p6veuTzwKpy.swZceSPYo8E1WKv1mcetkpUgzKLgbwzjuGzCD7KlYtmetg8DbG6sGy9jGol+.tA9Tux8dbuF7zNYd2hY5hw5b8ozVA5xYColgX7MgbwFz.aUWpYyspJExt2RNwquACtheylrr0PGjBsfRQMamP4xk2fYyn9ox2duxeNboXpWXezwyVT3T+7oCze8N3H3RzEDHu99jb49e8SxM5YeP8vWs8huMFpKWjD5JI+23KeY7ncuLjgC0zStc7g+0I8mIjBn2hv+bQyfqpGSJf1M5HMX8K3gbf1EaaZpiW+.n6yfWSwwXM2XLVyMGi07QiwZt0XrlaOFq4NCcM5N0wmsVGyCDpsRzC.Xz8gQfvez+v3k7mU -
@aaronventure Ah thanks, I was misunderstanding the purpose of this I think. I thought it was for makeup gain so that the input volume is the same as the output