What is the correct approach for making a custom polyphonic c++ node?
-
I've got a monophonic foldback distortion node that I've written. I wanted to make a polyphonic version, but wasn't 100% sure how to get there.
I assume I need to move my fbDist custom struct (with the relevant prepare, process, setDrive, setLevel methods in it) inside a VoiceState struct, and then somehow essentially spawn a new VoiceState object any time a voice is initialised. But I'm not too sure how to do it - is there a template I could look at?
Simply turning the isPolyphonic flag on doesn't seem to work for my node. I assume because all voices still try to use the single fbDist object instance that I am currently creating. So it ends up sounding like bitcrushed horrible death mess.
-
Hmmm, okay I think I figured it out by reading these:
https://docs.hise.dev/scriptnode/snex_api/containers/polydata.html
https://forum.hise.audio/topic/11024/polyphonic-custom-filters-scriptnode-how/27Here's what I can figure out. Let's say you've got a struct that processes samples. It might just be a basic gain effect. In my case it is essentially a waveshaping effect with oversampling.
You need to use PolyData with your struct. Like this:
PolyData<OversampledSaturator, NV> satL, satR;This seems to create an instance of the object for each voice, and assigns the array to the variables named - in my case I wanted a true stereo waveshaper.
Any constants like oversample cutoff, number of taps, etc... those don't need to be PolyData-ized. You could put them in the struct to be sure, but I don't see the point for those.
Inside the processor, you're going to want a prepare method that prepares everything you need. Mine is quite complicated, but the nuts and bolts would be feeding the PrepareSpecs reference from the main nodes prepare, into your structs prepare. This makes sure that each voice gets a reference to specs; from what I can tell.
But you also want to prepare each "lane" and set defaults. So here's my full prepare for the main node code:
void prepare(PrepareSpecs specs) { fs = specs.sampleRate; satL.prepare(specs); satR.prepare(specs); for (auto& s : satL) { s.prepare(fs, numOS, numOSTaps, osCutoff); s.setClipType(OversampledSaturator::ClipType::Soft); s.setDrive(20.0f); s.setMakeup(10.0f); s.setMix(1.0f); } for (auto& s : satR) { s.prepare(fs, numOS, numOSTaps, osCutoff); s.setClipType(OversampledSaturator::ClipType::Soft); s.setDrive(20.0f); s.setMakeup(10.0f); s.setMix(1.0f); } }And here's what my OversampledSaturator does:
void prepare(double sampleRate, int osFactor = 4, int firTaps = 32, float cutoffFracOfNyquist = 0.45f) { fs = float(sampleRate); os.prepare(osFactor, firTaps, fs, cutoffFracOfNyquist); reset(); }In the main node you also want to make sure you call each voices objects reset method:
void reset() { for (auto& s : satL) s.reset(); for (auto& s : satR) s.reset(); }Now the key thing that jumped out was from the docs on the get method:
If you know that you're inside a rendering context, you can use this function instead of the for-loop syntax. Be aware that the performance will be the same, it's just a bit less to type.Which led me to this:
void handleHiseEvent(HiseEvent& e) { if (e.isNoteOn()) { satL.get().reset(); satR.get().reset(); } }This is effectively short hand for "get the currrent voices instance of this object" - which is really cool.
Main process method doesn't change:
template <typename T> void process(T& data) { static constexpr int NumChannels = getFixChannelAmount(); auto& fixData = data.template as<ProcessData<NumChannels>>(); auto fd = fixData.toFrameData(); while (fd.next()) processFrame(fd.toSpan()); }But ProcessFrame does:
template <typename FrameSpan> void processFrame(FrameSpan& frame) { auto& L = satL.get(); // current voice lane (left) auto& R = satR.get(); // current voice lane (right) float xL = frame[0]; float xR = frame[1]; frame[0] = L.processSample(xL); frame[1] = R.processSample(xR); }Again, we get the processor object for the current voice (in my case, the saturator for the left and right channels) and then we run the current samples into the particular process method that exists inside our processor - it could be called blancmange for all we care, but mine is called processSample (because I have another one called processBlock)
.... and that pretty much has gotten me where I needed to be.
For setting parameters of the processor assigned to each voice, we do something like this:
else if constexpr (P == 0) // Drive { for (auto& s : satL) s.setDrive((float)v); for (auto& s : satR) s.setDrive((float)v); }So... In short:
1 - Wrap the processor like this - PolyData<yourprocessorstruct, NV> varnametoassignto;
2 - call varnametoassignto.prepare(specs) to create the HISE voice system hook (make sure your processor has a prepare method!)
3 - for (auto& n : varnametoassignto) to iterate around each one of them.
4 - varnametoassignto.get() to get the current voices instance. -
The only thing I haven't yet figured out is how to kill a voice when the time is right.
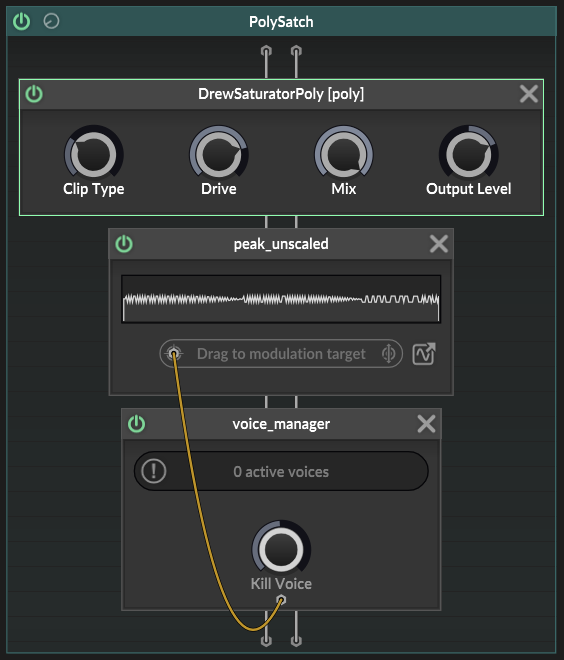
This kind of works. But look how nasty that peak data is. I'd be quite skeptical of this being the correct approach.
@griffinboy @Christoph-Hart - penny for your thoughts?
EDIT: The "Silent Killer" seems to work well for this actually. I guess the other approach is moving the envelope from the module tree into the node network, and using the gate on that to kill a voice too.
-
Voices in Hise are managed 'automatically'.
Take a read of Polydata.I don't remember where it can be found. But the Hise source has all the .h and .cpp files which have the implementations for voice handling. You can see what's currently going on, and perhaps there will be some useful api that you're not yet making use of.
Christoph is the person to ask though!