SIMD is already built into Hise?
-
So, does this mean Hise already has platform agnostic SIMD built in?
If so, is it done via a library, or is it a custom implementation?Is this referring to Juce::vectorised?
Because I am aware of this and have used it successfully in Hise before.Integrating xSIMD into Hise has been on my to-do list, but since I've not done something like this before, and I worry about having to get the compilers to set up all the flags.
SIMD is so good for dsp, I'm wanting to get it integrated properly in Hise, in a platform agnostic way.
-
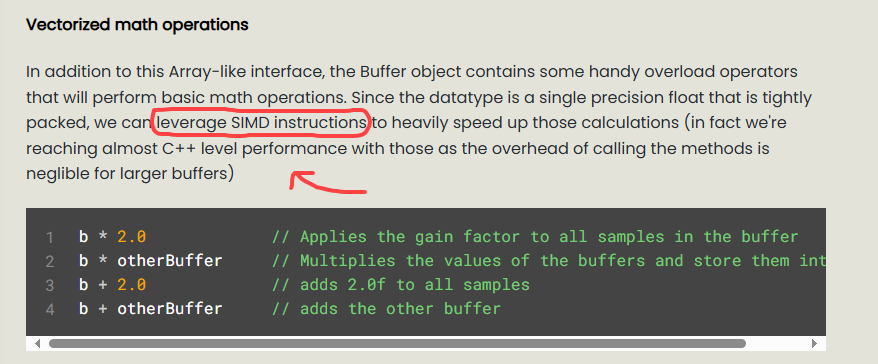
SIMD is a big topic and there are various ways to utilize it. For starters you have to assume that modern compilers do a pretty good job at autovectorising loops (which means turning single instructions into SIMD loops). So if you do something as simple as
for(int i = 0; i < samples.size(); i++) { samples[i] *= 0.4f; }you can assume with almost 100% certainty that any compiler with a optimizer will turn this into machine code which uses vector operations of the target CPU architecture for this and there are dedicaded fields of computer science that tried to extend that functionality on more complex cases over the last 50 years which you can reap the benefits from by compiling the code with O1 or faster.
Obviously this assumes that the loop is being statically compiled, so a HiseScript loop will never be optimized like this (hence why the example above makes sense as it uses predefined vector functions to operate on the float array that is referenced by the HiseScript buffer object).
So unless you have a very specific use case where you can safely assume that the compiler will not be able to vectorise it, I would not care to much about trying to handwrite SIMD instructions (but using the JUCE vector ops when suitable is definitely a best practice). IIRC there was one specific case in the HLAC codec where I had to use a special SSE instruction to distribute a single value into 4 slots which lead to a 10-20% speedup of the decoding performance, but the times where I profiled stuff and realized that my hand-written SIMD is about as fast as the "naive" implementation that was optimized by the compiler vastly outnumbers the cases where I beat the autovectoriser.
-
Right yes, I do a fair amount of matrix maths in my code, and this is what I was wanted to parallelise, as well as of course the channels themselves, I've been doing a lot more block processing rather than frames now getting ready to try and get this to work.
-
@Christoph-Hart
That's really interesting I'll have to test it myself.
Since Hise is already set up to use ipp, can I assume that ipp will work in scriptnode? I'm looking to vectorise samples to do 4 at once (block processing where each channel is done consecutively, vectorising samples rather than channels)